
 Deutsch
Deutsch  English
English Chapter 3 - Process Manager
Process Manager
Introduction
The Neutrino microkernel described in the previous section contains the core services of POSIX 1003.1a,b,c, and d. Since the microkernel is under 32K, very small embedded systems can be targeted. The QNX/Neutrino Process Manager extends the POSIX functionality of the Neutrino microkernel by adding most of those components of the POSIX API not supported directly by the microkernel.
When Neutrino is used without the Process Manager, the runtime memory model that is produced when application threads are linked in consists of a single address space with multiple threads of execution. This image represents a single multi-threaded POSIX process with process id 1. On an Intel processor, the threads in the process execute at privity level 1. When the threads enter the microkernel via a kernel call, the microkernel executes at ring 0.
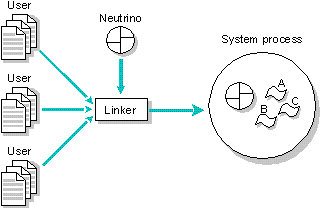
The runtime memory model produced when user threads are linked against the kernel consists of a single address space with multiple threads of execution.
Creating multiple POSIX processes (each of which may contain multiple POSIX threads) requires the Process Manager, which adds another 32K of code and provides three new capabilities in addition to those provided by the microkernel:
- process management - manages process creation, destruction, and process attributes such as user ID (uid) and group ID (gid).
- memory management - manages a range of memory protection capabilities, DLLs, and interprocess POSIX shared-memory primitives.
- pathname management - manages the pathname space into which resource managers may attach.
Since most target systems using a 32-bit microprocessor probably won't consider an additional 32K of code significant, the vast majority of systems will likely include the Process Manager.
The Process Manager is built in the same manner as a custom embedded system, that is, it's linked directly against the microkernel. In this case, however, the code that makes up the capabilities of the Process Manager is the only code linked - no user code is linked into the system process. The resulting process contains the capabilities of both the Process Manager and the microkernel. The executable for the Process Manager is named ProcNto.
User processes access microkernel functions directly via kernel calls and Process Manager functions by sending messages to ProcNto. Note that a user process sends a message by invoking the MsgSendv() kernel call. On an Intel processor, all other processes execute at ring 3. The following ring levels are defined:
- Ring 0 - kernel call executing code in the microkernel
- Ring 1 - threads running in ProcNto process
- Ring 2 - not used
- Ring 3 - threads running in all other processes
It's important to note that threads executing within ProcNto invoke the microkernel in exactly the same fashion as threads in other processes. The fact that the Process Manager code and the microkernel share the same process address space doesn't imply a "special" or "private" interface. All threads in the system share the same consistent kernel interface and all perform a privity switch to ring 0 when invoking the microkernel.
Process management
The first responsibility of ProcNto is to dynamically create new processes. These processes will then depend on ProcNto's other responsibilities of memory management and pathname management.
Process management consists of both process creation and destruction as well as the management of process attributes such as process ids, process groups, user ids, etc.
Process creation primitives
There are 4 process creation primitives:
| Function | Description |
|---|---|
| spawn() | POSIX 1003.1d draft |
| fork() | POSIX 1003.1 |
| vfork() | UNIX BSD extension |
| exec*() | POSIX 1003.1 |
spawn()
The spawn() call was introduced in the draft POSIX standard 1003.1d. The function creates a child process by directly specifying an executable to load. To those familiar with UNIX systems, the call is modeled after a fork() followed by an exec*(). However, it operates much more efficiently in that there's no need to duplicate address spaces as in a fork(), only to destroy and replace it when the exec*() is called.
The spawn() call also has one other key attribute - unlike a fork() (which requires an MMU and per-process private address spaces), the spawn() call can operate without any type of MMU at all.
One of the main advantages of using the fork()-then-exec*() method of creating a child process is the flexibility in changing the default environment inherited by the new child process. This is done in the forked child just before the exec*(). For example, the following simple shell command would close and reopen the standard output before exec*()'ing:
ls >file
The POSIX spawn() function gives control over four classes of environment inheritance, which are often adjusted when creating a new child process:
- file descriptors
- process group id
- signal mask
- ignored signals
The QNX/Neutrino implementation also allows you to change:
- node to create process on
- scheduling policy
- scheduling parameters (priority)
- maximum stack size
There are two forms of the POSIX spawn() function:
| Function | Description |
|---|---|
| spawn() | Spawn with explicit specified path |
| spawnp() | Search the current PATH and invoke spawn() with the first matching executable |
There's also a set of non-POSIX convenience functions that are built