
 Deutsch
Deutsch  English
English Chapter 5 - The Filesystem Manager
Filesystems
- Introduction
- Filesystem classes
- Image filesystem
- RAM filesystem
- Tiny QNX filesystem
- QNX filesystem
- DOS Filesystem
- CD-ROM Filesystem
- Flash filesystem
- NFS filesystem
- CIFS filesystem
Introduction
QNX/Neutrino provides a rich variety of filesystems. Like most service-providing processes in the OS, these filesystems execute outside the kernel; applications use them by communicating via messages generated by the shared-library implementation of the POSIX API.
The filesystems are resource managers as described in this book. Each filesystem adopts a portion of the pathname space and provides filesystem services through the standard POSIX API (open(), close(), read(), write(), lseek(), etc.).
This implementation means that:
- filesystems may be started and stopped dynamically
- multiple filesystems may run concurrently
- applications are presented with a single unified pathname space and interface, regardless of the configuration and number of underlying filesystems.
Filesystem classes
The many filesystems available can be categorized into 4 classes as follows:
- Image
- A special filesystem that presents the modules in the image and is always present.
- Block
- Traditional filesystems that operate on block devices like hard disks and CD-ROM drives. This includes the POSIX, DOS, and CD-ROM filesystems.
- Flash
- Non-block-oriented filesystems designed explicitly for the characteristics of Flash memory devices. This includes the Flash filesystem.
- Network
- Filesystems that provide network file access to the filesystems on remote host computers. This includes the NFS and CIFS filesystems.
Filesystems as DLLs
Since it's common to run many filesystems under Neutrino, they have been designed as a family of drivers and DLLs to maximize code reuse. This means the cost of adding an additional filesystem is typically smaller than might otherwise be expected.
Once an initial filesystem is running, the incremental memory cost for additional filesystems is minimal, since only the code to implement the new filesystem protocol would be added to the system. In the following example, the CD-ROM filesystem could be added for less than 4K of additional code.
The various filesystems are layered as follows:
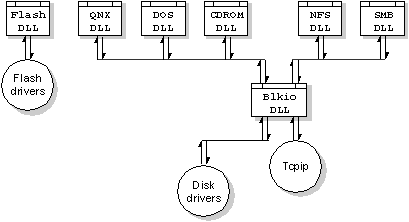
Neutrino filesystem layering.
As shown in this diagram, the Filesystems and Blkio are implemented as DLLs (essentially passive blocks of code resident in memory), while the driver is the executing process that calls into the DLLs. In operation, the driver process starts first and invokes the block level DLL. The filesystem DLLs may be dynamically loaded later to provide filesystem interfaces and services.
Note that this is the opposite of many systems, which implement the filesystem as the primary entity that then loads drivers to talk to disk devices. This reversal of roles in QNX provides interesting capabilities.
A ``filesystem'' DLL implements a filesystem protocol or ``personality'' on a set of blocks on a physical disk device. The filesystems aren't built into the OS kernel; rather, they're dynamic entities that can be loaded or unloaded on demand.
For example, a removable storage device (PCCard Flash card, floppy disk, removable cartridge disk, etc.) may be inserted at any time, with any of a number of filesystems stored on it. While the hardware the driver interfaces to is unlikely to change dynamically, the on-disk data structure could vary widely. The dynamic nature of the QNX filesystem copes with this very naturally.
Blkio
Most of the filesystem DLLs ride on top of the Block I/O DLL (Blkio). This is also a resource manager and exports a file for each device on the physical device. For a system with two hard disks the default files would be:
- /dev/hd0
- First hard disk
- /dev/hd1
- Second hard disk
These files represent each raw disk and may be accessed using all the normal POSIX file primitives (open(), close(), read(), write(), lseek(), etc.). The Blkio DLL in Neutrino will support a 64-bit offset on seek, allowing access to disks with greater than 18 exabytes (2^63 bytes).
Partitions
QNX complies with the de facto industry standard for partitioning a disk. This allows a number of filesystems to share the same physical disk. Each partition is also represented as a file, with the partition type appended to the filename of the disk it's located on. In the above ``two-disk'' example, if the first disk had a QNX partition and a DOS partition, while the second disk had only a QNX partition, then the default files would be:
- /dev/hd0
- First hard disk
- /dev/hd0t6
- DOS partition on first hard disk
- /dev/hd0t77
- QNX partition on first hard disk
- /dev/hd1
- Second hard disk
- /dev/hd1t77
- QNX partition on second hard disk
The following list shows some of the partition types currently used:
| Type | Filesystem |
|---|---|
| 1 | DOS (12-bit FAT) |
| 4 | DOS (16-bit FAT; partitions <32M) |
| 5 | DOS Extended Partition |
| 6 | DOS 4.0 (16-bit FAT; partitions >=32M) |
| 7 | OS/2 HPFS |
| 7 | Previous QNX version 2 (pre-1988) |
| 8 | QNX 1.x and 2.x ("qny") |
| 9 | QNX 1.x and 2.x ("qnz") |
| 11 | DOS 32-bit FAT; partitions up to 2047G |
| 12 | Same as Type 11, but uses Logical Block Address Int 13h extensions |
| 14 | Same as Type 6, but uses Logical Block Address Int 13h extensions |
| 15 | Same as Type 5, but uses Logical Block Address Int 13h extensions |
| 77 | QNX POSIX partition |
| 78 | QNX POSIX partition (secondary) |
| 79 | QNX POSIX partition (secondary) |
| 99 | UNIX |
Buffer cache
Blkio implements a buffer cache that all filesystems inherit. The buffer cache attempts to store frequently accessed filesystem blocks in order to minimize the number of times a system has to perform a physical I/O to the disk or over the network.
Read operations are synchronous; write operations are usually asynchronous (except with tblkio, in which case all I/O is synchronous). When an application writes to a file, the data enters the cache, and the Filesystem Manager immediately replies to the client process to indicate that the data has been written. The data is then written to the disk as soon as possible.
The cache management software normally gives priority to read operations over write operations. However, this behavior is modified in two cases:
- The cache is nearly full - writes are given the same priority as reads until a reasonable number of blocks have been made available in the cache.
- Critical filesystem blocks such as bitmap blocks, directory blocks, extent blocks, and inode blocks are written immediately and synchronously to disk (these critical blocks bypass the normal write mechanism, including the elevator seeking).
Applications can modify write behavior on a file-by-file basis. For example, a database application can cause all writes for a given file to be performed synchronously. This would ensure a high level of file integrity in the face of potential hardware or power problems that might otherwise leave a database in an inconsistent state.
Drivers
At the bottom of the filesystem hierarchy are the device drivers. Each driver is a process that loads the DLLs necessary to implement any combination of filesystems. The drivers can be grouped into three classes as follows:
- Disk
- drivers that interface to hard disk controllers.
- Flash
- drivers that interface to Flash memory devices.
- Network
- drivers that interface to the TCP/IP stack.
Disk
We provide a wide variety of drivers for the most popular disk controllers. These are high-performance drivers capable of doing multi-sector I/O. For controllers that support multiple concurrent requests, the drivers are multi-threaded to keep all drives busy. Both IDE and SCSI drivers provide support for CD-ROM drives.
Flash
We also provide several drivers for off-the-shelf existing embedded systems with Flash memory. The devices may be memory mapped, paged into a memory window, or I/O mapped. The drivers support many types of flash devices. In addition, source code is available to develop custom drivers for proprietary embedded systems.
Network
The NFS and CIFS filesystems use these drivers to interface to TCP/IP. The TCP/IP stack is implemented as a separate process that is communicated with via the high-performance messaging primitives.
Filesystem limitations
POSIX defines the set of services a filesystem must provide. However, not all filesystems are capable of delivering all those services. The following chart highlights some of the POSIX-defined capabilities and indicates if the filesystems support them:
| Capability | Image | RAM | QNX | Tiny QNX | DOS | CD-ROM | Flash | NFS | CIFS |
|---|---|---|---|---|---|---|---|---|---|
| Access date | no | yes | yes | yes | no | no | no | yes | yes |
| Write date | no | yes | yes | yes | yes | no | yes | yes | yes |
| Modification date | no | yes | yes | yes | no | no | no | yes | yes |
| Filename length | 255 | 255 | 48 | 16/48* | 8.3/255+ | 255 | 255 | ++ | ++ |
| User permissions | yes | yes | yes | yes | no | yes** | yes | yes++ | yes++ |
| Group permissions | yes | yes | yes | yes | no | yes | yes | yes++ | yes++ |
| Other permissions | yes | yes | yes | yes | no | yes | yes | yes++ | yes++ |
| Directories | no | yes | yes | yes | yes | yes | yes | yes | yes |
| Hard links | no | no | yes | yes* | no | no | no | yes | no |
| Soft links | no | no | yes | yes | yes*** | yes | no | yes | no |
| Read compression | no | no | no | no | no | no | yes | no | no |
- * 48-character filename lengths and hard links can be accessed, but not created.
- ** With Rock Ridge extensions.
- *** QNX extension.
- + 255-character filename lengths used by Windows NT/95 filesystem.
- ++ Limited by remote filesystem.
Image filesystem
Every QNX system image that includes the Process Manager/Microkernel (ProcNto) provides a simple read-only filesystem that presents the set of files built into the OS image.
Since this image may include both executables and data files, this filesystem is sufficient for many embedded systems. If additional filesystems are required, they would be placed as modules within the image where they can be started as needed.
RAM filesystem
Every QNX system that includes the Process Manager/Microkernel (ProcNto) also provides a simple RAM-based filesystem that allows read/write files to be placed under /dev/shmem.
This RAM filesystem finds the most use in tiny embedded systems where persistent storage across reboots isn't required, yet where a small, fast, temporary-storage filesystem is called for.
The filesystem comes for free with ProcNto and doesn't require any setup. You can simply create files under /dev/shmem and grow them to any size (depending on RAM resources).
Although the RAM filesystem itself doesn't support hard or soft links, you can create a link to it by utilizing Process Manager links. For example, you could create a link to a RAM-based /tmp directory:
ln -sP /dev/shmem /tmp
This tells ProcNto to create a Process Manager link to /dev/shmem known as "/tmp." Application programs can then open files under /tmp as if it were a normal filesystem.
Tiny QNX filesystem
The Tiny QNX filesystem (Fsys.tqnx) is a scaled-down version of the high-performance QNX filesystem provided with QNX 4.23. It shares the same on-disk structure, ensuring portability between QNX 4.23 and QNX/Neutrino.
The Tiny QNX filesystem implements an extremely robust design, utilizing an extent-based, bitmap allocation scheme with fingerprint control structures to safeguard against data loss and to provide easy recovery. Features include:
- extent-based POSIX filesystem
- robustness: all sensitive filesystem info is written through to disk
- on-disk ``signatures'' and special key information to allow fast data recovery in the event of disk damage
- same disk format as QNX 4.23 filesystem
- 48-character filenames
- multi-threaded design
- client-driven priority
When trading off features for size to tailor Fsys.tqnx for an embedded system, the following features were omitted or limited in their scope:
- Filenames
- The Tiny POSIX Filesystem can access 48-character filenames, but can only create new files with a maximum of 16 characters in the name. Long filenames of up to 48 characters can be created by the QNX 4.23 POSIX filesystem for use by Fsys.tqnx.
- Hard links
- The Tiny filesystem can't create hard links, but it can create symbolic links. Hard links created on disk by the QNX 4.23 POSIX Filesystem Manager can still be accessed.
- Rename
- The Tiny filesystem can't rename a file across a directory boundary. It can rename files within a single directory, provided the filenames are within the 16-character limit.
The resulting Tiny POSIX filesystem is truly tiny (occupying less than 12K of code), yet still provides the majority of the capabilities required of a POSIX filesystem.
QNX filesystem
Disk structure
The QNX filesystem consists of the following components found at the beginning of its partition:
- loader block
- root block
- bitmap
- root directory
- other directories, files, free blocks, etc.
These structures are created when the filesystem is initialized with the dinit utility.
Loader block
This is the first physical block of a disk partition. This block contains the code that is loaded and then executed by the BIOS of the computer to load an OS from the partition. If a disk hasn't been partitioned (e.g. a floppy diskette), this block is the first physical block on the disk.
Root block
The root block is structured as a standard directory. It contains inode information for these four special files:
- the root directory of the filesystem (/)
- /.inodes
- /.boot
- /.altboot
The files /.boot and /.altboot contain images of the operating system that can be loaded by the QNX bootstrap loader.
Normally, the QNX loader loads the OS image stored in the /.boot file. But if the /.altboot file isn't empty, you'll be given the option to load the image stored in the /.altboot file.
Bitmap
To allocate space on a disk, QNX uses a bitmap stored in the /.bitmap file. This file contains a map of all the blocks on the disk, indicating which blocks are used. Each block is represented by a bit. If the value of a bit is 1, its corresponding block on the disk is in use.
Root directory
The root directory of a partition behaves as a normal directory file with two exceptions:
- Both ``dot'' (.) and ``dot dot'' (..) are links to the same inode information, namely the root directory inode in the root block.
- The root directory always has entries for the /.bitmap, /.inodes, /.boot, and /.altboot files. These entries are provided so programs that report information on filesystem usage will see the entries as normal files.
Extents
In the QNX filesystem, regular files and directory files are stored as a sequence of extents. An extent is a contiguous sequence of blocks on disk.
Files that have only a single extent store the extent information in the directory entry. If more than one extent is needed to hold the file, the extent location information is stored in one or more linked extent blocks. Each extent block can hold location information for up to 60 extents.
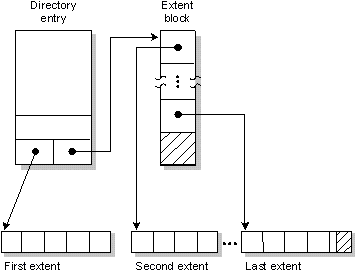
A file consisting of multiple consecutive regions or extents on a disk.
Extending files
When the QNX filesystem needs to extend a file, it uses the bitmap to see if it can extend the file contiguously on disk. If not, it tries to allocate a new extent as near to the current extent as possible. This may require allocating a new extent block as well. When an extent is allocated or grown, the filesystem may over-allocate space under the assumption that the process will continue to write and fill the extra space. When the file is closed any extra space will be returned.
This design ensures that when files are written, even several files at one time, they are as contiguous as possible. Since most hard disk drives implement track caching, this not only ensures that files are read as quickly as possible from the disk hardware, but also serves to minimize the fragmentation of data on disk.
Links and inodes
File data is stored distinctly from its name and can be referenced by more than one name. Each filename, called a link, points to the actual data of the file itself. (There are actually two kinds of links: hard links, which we refer to simply as ``links,'' and symbolic links. Symbolic links are described in the next section.)
In order to support links for each file, the filename is separated from the other information that describes a file. The non-filename information is kept in a storage table called an inode (for "information node").
If a file has only one link (i.e. one filename), the inode information (i.e. the non-filename information) is stored in the directory entry for the file. If the file has more than one link, the inode is stored as a record in a special file named /.inodes, as are the file's directory entry points to the inode record.
Note that you can create a link to a file only if the file and the link are in the same filesystem.
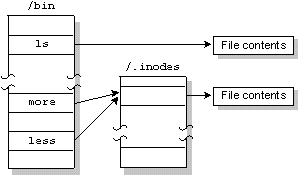
The same file is referenced by two links named ``more'' and ``less.''
There are two other situations in which a file can have an entry in the /.inodes file:
- If a file's filename is longer than 16 characters, the inode information is stored in the /.inodes file, making room for a 48-character filename in the directory entry.
- If a file has had more than one link and all links but one have been removed, the file continues to have a separate /.inodes file entry. This is done because the overhead of searching for the directory entry that points to the inode entry would be prohibitive (there are no back links from inode entries to directory entries). You can remove this minor overhead by running the chkfsys command.
Removing links
When a file is created, it is given a link count of one. As links to the file are added, this link count is incremented; as links are removed, the link count is decremented. The disk space occupied by the file data isn't freed and marked as unused in the bitmap until its link count goes to zero and all programs using the file have closed it. This allows an open file to remain in use, even though it has been completely unlinked. This behavior is part of that stipulated by POSIX and common UNIX practice.
Directory links
Although you can't create hard links to directories, each directory has two hard-coded links already built in:
- . (``dot'')
- .. (``dot dot'')
The filename ``dot'' refers to the current directory; ``dot dot'' refers to the previous directory in the hierarchy.
Note that if there's no predecessor, ``dot dot'' also refers to the current directory. For example, the ``dot dot'' entry of ``/'' is simply ``/'' - you can't go further up the path.
Symbolic links
A symbolic link is a special file that has a pathname as its data. When the symbolic link is named in an I/O request - by open(), for example - the link portion of the pathname is replaced by the link's ``data'' and the path is re-evaluated.
Symbolic links are a flexible means of pathname indirection and are often used to provide multiple paths to a single file. Unlike hard links, symbolic links can cross filesystems and can also create links to directories.
In the following example, the directories /net/node1/usr/fred and /net/node2/usr/barney are linked even though they reside on different filesystems - they're even on different nodes (see the following diagram). This couldn't be done using hard links:
/net/node1/usr/fred --> /net/node2/usr/barney
Note how the symbolic link and the target directory need not share the same name. In most cases, you use a symbolic link for linking one directory to another directory. However, you can also use symbolic links for files, as in this example:
/net/node1/usr/eric/src/test.c --> /net/node1/usr/src/game.c
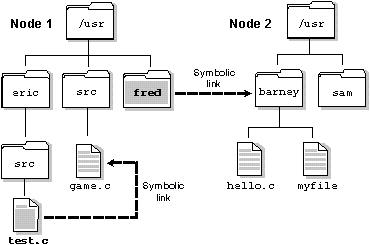
Symbolic links can be used for files and directories anywhere throughout the network.
 | Remember that removing a symbolic link acts only on the link, not the target. |
Several functions operate directly on the symbolic link. For these functions, the replacement of the symbolic element of the pathname with its target is not performed. These functions include unlink() (which removes the symbolic link), lstat(), and readlink().
Since symbolic links can point to directories, incorrect configurations can result in problems such as circular directory links. To recover from circular references, the system imposes a limit on the number of hops; this limit is defined as SYMLOOP_MAX in the <limits.h> include file.
Filesystem robustness
The QNX filesystem achieves high throughput without sacrificing reliability. This has been accomplished in several ways.
While most data is held in the buffer cache and written after only a short delay, critical filesystem data is written immediately. Updates to directories, inodes, extent blocks, and the bitmap are forced to disk to ensure that the filesystem structure on disk is never corrupt (i.e. the data on disk should never be internally inconsistent). The tiny block I/O module (tblkio) always writes all data synchronously.
Sometimes all of the above structures must be updated. For example, if you move a file to a directory and the last extent of that directory is full, the directory must grow. In such cases, the order of operations has been carefully chosen such that if a catastrophic failure occurs when the operation is only partially completed (e.g. a power failure), the filesystem, upon rebooting, would still be ``intact.'' At worst, some blocks may have been allocated, but not used. You can recover these for later use by running the chkfsys utility.
Filesystem recovery
Even in the best systems, true catastrophes such as these may happen:
- Bad blocks may develop on a disk because of power surges or brownouts.
- A naive or malicious user with access to superuser privileges might reinitialize the filesystem (via the dinit utility).
- An errant program (especially one run in a non-QNX environment) may ignore the disk partitioning information and overwrite a portion of the QNX partition.
To recover as many files as possible if such events occur, unique ``signatures'' have been written on the disk to aid in the automatic identification and recovery of the critical filesystem pieces. The inodes file (/.inodes), as well as each directory and extent block, all contain unique patterns of data that the chkfsys utility can use to reassemble a truly damaged filesystem.
DOS Filesystem
The DOS Filesystem, Fsys.dos, provides transparent access to DOS disks, so you can treat DOS filesystems as though they were POSIX filesystems. This transparency allows processes to operate on DOS files without any special knowledge or work on their part.
The structure of the DOS filesystem on disk is old and inefficient, and lacks many desirable features. Its only major virtue is its portability to DOS and Windows environments. You should choose this filesystem only if you need to transport DOS files to other machines that require it. Consider using the Tiny POSIX Filesystem alone if DOS file portability isn't an issue or in conjunction with the DOS Filesystem if it is.
If there's no DOS equivalent to a POSIX feature, Fsys.dos will either return an error or a reasonable default. For example, an attempt to create a link() will result in appropriate error code (i.e. errno) being returned. On the other hand, an attempt to read the 4 POSIX times on a file will default the 3 unsupported times to be the same as the last write time.
DOS version support
Fsys.dos supports both floppies and hard disk partitions from DOS version 2.1 to Windows NT/95 with long filenames.
DOS text files
DOS terminates each line in a text file with two characters (CR/LF), while POSIX (and most other) systems terminate each line with a single character (LF). Fsys.dos makes no attempt to translate text files being read. Most utilities and programs won't be affected by this difference.
Note also that some very old DOS programs may use a Ctrl-Z (^Z) as a file terminator. This character is also passed through without modification.
QNX-to-DOS filename mapping
In DOS, a filename cannot contain any of the following characters:
/ \ [ ] : * | + = ; , ?
An attempt to create a file that contains one of these invalid characters will return an error. DOS also expects all alphabetical characters to be uppercase, so Fsys.dos maps these characters to uppercase when creating a filename on disk. Since uppercase is awkward to type, it maps a filename to lowercase when returning a filename to a QNX application. This allows QNX users and programs to always see and type lowercase.
Translating QNX filenames
If you specify the -t option to Fsys.dos, it will translate and truncate QNX filenames that don't conform to the DOS naming conventions. The following table describes how names are translated:
| If the filename: | Fsys.dos will: |
|---|---|
| starts with a dot (.) | change the . to a $ |
| contains multiple dots | change all but the last dot to a $ |
| has a prefix longer than 8 characters | truncate the prefix to 8 characters unless Windows NT/95 names are allowed |
| has a suffix longer than 3 characters | truncate the suffix to three characters |
DOS volume labels
DOS uses the concept of a volume label, which is an actual directory entry in the root of the DOS filesystem. To distinguish between the volume label and an actual DOS directory, Fsys.dos will place an equal sign (=) as the first character of the volume name.
DOS-QNX permission mapping
DOS doesn't support all the permission bits specified by POSIX. It has a READ_ONLY bit in place of separate READ and WRITE bits; it doesn't have an EXECUTE bit. When creating a DOS file, the DOS READ_ONLY bit will be set if all the POSIX WRITE bits are off. When accessing a DOS file, the POSIX READ bit is always assumed to be set for user, group, and other.
Since the command loader won't execute a file that doesn't have EXECUTE permission, Fsys.dos has a -e option that will set this bit on all files. If you chose DOS as your only filesystem, you'll need to set this option in order to execute commands from it.
File ownership
Although the DOS file structure doesn't support user IDs and group IDs, Fsys.dos won't return an error code if an attempt is made to change them. An error isn't returned because a number of utilities attempt to do this and failure would result in unexpected errors. The approach taken is "you can change anything to anything since it isn't written to disk anyway."
When the user IDs are queried, they'll always be owned by the superuser (uid = 0, gid = 0) with access to all.
CD-ROM Filesystem
The CD-ROM Filesystem, Fsys.cdrom, provides transparent access to CD-ROM media, so you can treat CD-ROM filesystems as though they were POSIX filesystems. This transparency allows processes to operate on CD-ROM files without any special knowledge or work on their part.
Fsys.cdrom implements the ISO 9660 standard, including Rock Ridge extensions. DOS and Windows Compact Discs follow this standard. In addition to normal files, Fsys.cdrom also supports audio.
Flash filesystem
The Flash filesystem manager, Devm.*, was explicitly designed to work with Flash memory, whether buil-in or removable. Files written to removable Flash media (PC-Card cards) are portable to other systems that also support this standard.
Devm.* combines the functions of a filesystem manager and a device driver to manage a Flash filesystem on memory-based media. Because Devm.* includes the device driver for controlling the hardware, there are separate versions of Devm.* for different embedded systems hardware. For example:
- Devm.explr2 for the Intel EXPLR2 evaluation board (with on-board RFA)
- Devm.ns486 for the National Semiconductor NS486SXF evaluation board (PC-Card interface)
Restrictions
The functionality of the filesystem is restricted by the memory devices used. For example, if the medium contains ROM devices only, the filesystem is read-only.
Memory-based Flash devices have restrictions on file writing. You can only append to the file. In addition, file access times aren't updated. Currently, these restrictions apply even if devices such as SRAM are used.
Space reclamation
Devm.* stores directories and files using linked lists of data structures, rather than the fixed-size disk blocks used in traditional rotating-medium filesystems. When a directory or file is deleted, the data structures representing it are marked as deleted, but aren't removed. This avoids continuously erasing and rewriting the medium.
Eventually, the medium will run out of free space and the filesystem manager will perform space reclamation (or "garbage collection"). During this process, Devm.* recovers the space occupied by deleted files and directories. To perform space reclamation, the filesystem manager requires at least one spare block on the medium. The mkffs utility automatically reserves one spare block when you make a filesystem.
Compression and decompression
Devm.* supports decompression, which increases the amount of data that can be stored on a medium. Decompression operates transparently to applications.
For files to be decompressed transparently by the filesystem manager, you must compress them explicitly before using mkffs. You do this with the bpe utility. If you copy a compressed file to a live Flash filesystem, it will remain compressed when it's read from the filesystem.
File permissions
If you disable the POSIX extensions, file ownership is permanently set to root and all permissions are set to rwx. The chgrp, chmod, and chown commands won't work.
Mounting
You can set mountpoints only when initializing the partitions or when starting the filesystem manager.
Raw device access
When you start Devm.*, it creates a special device file in the /dev directory for each medium. In a system with two memory-based media, Devm.* would create the special files /dev/skt1 and /dev/skt2. The special device ignores the partitioning, allowing raw device access to the medium.
An image filesystem partition can be accessed only as a raw device. For each image filesystem partition, Devm.* creates a special file in the format /dev/sktXimgY, where X is the medium socket number and Y is the number of the image filesystem partition in that medium.
Note that if you have Flash memory, you're not limited to this special Flash filesystem. You can use any of the regular block-oriented filesystems with Flash memory if you also include the Ftlio DLL.
NFS filesystem
The Network File System (NFS) allows a client workstation to perform transparent file access over a network. It allows a client workstation to operate on files that reside on a server across a variety of operating systems. Client file access calls are converted to NFS protocol requests, and are sent to the server over the network. The server receives the request, performs the actual filesystem operation, and sends a response back to the client.
The Network File System operates in a stateless fashion by using remote procedure calls (RPC) and TCP/IP for its transport. Therefore, to use Fsys.nfs you'll also need to run the TCP/IP client for QNX/Neutrino.
Any POSIX limitations in the remote server filesystem will be passed through to the client. For example, the length of filenames may vary across servers from different operating systems.
The user ID and group ID mappings must be the same between client and server. However, the server maps uid 0 (the super-user) to uid -2 before performing access checks for a client. This inhibits superuser privileges on remote filesystems.
CIFS filesystem
The Common Internet File System (CIFS) allows a client workstation to perform transparent file access over a network to a Windows 95 or NT server. Client file access calls are converted to CIFS protocol requests and are sent to the server over the network. The server receives the request, performs the actual filesystem operation, and sends a response back to the client.
Fsys.cifs uses TCP/IP for its transport. Therefore, to use Fsys.cifs you'll also need to run the TCP/IP client for QNX/Neutrino.