
 Deutsch
Deutsch  English
English Kapitel 2 - Der Mikrokernel
Der Mikrokernel
Dieses Kapitel beinhaltet die folgenden Themen:
- Einführung
- Interprozeßkommunikation (IPC)
- IPC über Nachrichten
- IPC über Proxies
- IPC über Signale
- IPC über das Netzwerk
- IPC über Semaphoren
- Prozeß-Scheduling
- Ein Wort zu Echtzeitperformance
Einführung
Der QNX Mikrokernel übernimmt folgende Aufgaben:
- IPC - der Mikrokernel überwacht das Routing von Nachrichten; er verwaltet auch noch zwei andere Formen des IPC: Proxies und Signale
- Netzwerkkommunikation auf unterster Stufe - der Mikrokernel liefert alle Nachrichten für Prozesse auf anderen Knoten aus
- Prozeß-Scheduling - der Scheduler des Mikrokernel entscheidet, welcher Prozeß als nächstes ausgeführt wird
- Handhabung von Interrupts auf erster Stufe - alle Hardwareinterrupts und Schutzverletzungen werden zuerst durch den Mikrokernel geleitet und dann an den entsprechenden Treiber oder System-Manager weitergeleitet
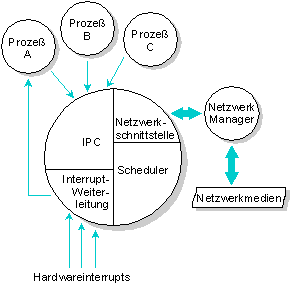
Das Innenleben des QNX-Mikrokernel.
Interprozeßkommunikation
Der QNX-Mikrokernel unterstützt essentiell drei Typen von IPC: Nachrichten, Proxies und Signale.
- Nachrichten - die fundamentale Form des IPC in QNX. Sie bieten synchrone Kommunikation zwischen kooperierenden Prozessen, wobei der sendende Prozeß eine Übermittlungsprüfung und potentiell eine Antwort auf die Nachricht erwartet.
- Proxies - eine spezielle Form von Nachrichten. Sie sind besonders zur Benachrichtigung geeignet, bei der der sendende Prozeß nicht mit dem Empfänger interagieren und auf eine Antwort warten muß.
- Signale - eine traditionelle Form von IPC. Sie werden benötigt, um asynchrone Interprozeßkommunikation zu ermöglichen.
IPC über Nachrichten
In QNX ist eine Nachricht ein Bytepaket, welches synchron von einem Prozeß zum anderen transportiert wird. QNX interessiert sich nicht für den Inhalt der Nachricht. Die Daten in einer Nachricht sind nur für den Sender und den Empfänger interessant, für niemanden sonst.
Funktionen für den Nachrichtentransport
Um direkt miteinander zu kommunizieren, benutzen kooperierende Prozesse die folgenden C Funktionen:
| C-Funktion: | Beschreibung: |
|---|---|
| Send() | um Nachrichten zu versenden |
| Receive() | um Nachrichten zu erhalten |
| Reply() | um Prozessen zu antworten, die Nachrichten versand haben |
Diese Funktionen können lokal oder über ein Netzwerk benutzt werden.
Beachten Sie, daß Prozesse, solange sie nicht direkt miteinander kommunizieren wollen, die Send(), Receive() und Reply() Funktionen nicht benutzen müssen. Die QNX-C-Bibliothek basiert auf dem Austausch von Nachrichten - Prozesse bedienen sich indirekt des Message Passing (Nachrichtenaustausch), wenn sie Standarddienste wie Pipes in Anspruch nehmen.

Prozeß A sendet eine Nachricht an Prozeß B, welcher diese anschließend empfängt, verarbeitet und dann auf die Nachricht antwortet.
Die obige Illustration stellt eine einfache Abfolge von Ereignissen dar, in der zwei Prozesse, Prozeß A und Prozeß B, Send(), Receive() und Reply() benutzen, um miteinander zu kommunizieren:
- Prozeß A sendet eine Nachricht an Prozeß B, indem er eine Send() Anforderung an den Mikrokernel schickt. Zu diesem Zeitpunkt wird Prozeß A SEND-blockiert bis Prozeß B ein Receive() absetzt, um die Nachricht zu empfangen.
- Prozeß B setzt ein Receive() ab und empfängt die wartende Nachricht von Prozeß A. Jetzt wird Prozeß A in den Zustand REPLY-blockiert gesetzt. Wenn eine Nachricht auf Prozeß B wartet, sobald er Receive()benutzt, blockiert er nicht, sondern empfängt diese Nachricht unmittelbar.
(Beachten Sie, daß Prozeß B RECEIVE-blockiert gewesen wäre, hätte er den Receive()-Befehl abgesetzt, bevor eine Nachricht für ihn eingetroffen wäre. In diesem Fall würde der Sender unverzüglich in den REPLY-blockierten Zustand gelangen, wenn er seine Nachricht abschickt.)
- Prozeß B verarbeitet die Nachricht, die er von Prozeß A empfangenen hat und initiiert ein Reply(). Die Antwortnachricht wird zu Prozeß A kopiert, welcher umgehend in den Zustand READY versetzt wird. Beachten Sie bitte, daß die Funktion Reply() nicht blockiert, so daß Prozeß B ebenfalls in den Zustand READY versetzt wird. Welcher Prozeß nun zur Ausführung gelangt, hängt von den relativen Prioritäten von Prozeß A und Prozeß B zueinander ab.
Prozeßsynchronisation
Die Vermittlung von Nachrichten erlaubt Prozessen nicht nur, Daten auszutauschen, sondern bietet auch die Möglichkeit, die Ausführung unterschiedlicher, kooperierender Prozesse zu synchronisieren.
Lassen Sie uns erneut obige Illustration betrachten. Sobald Prozeß A einen Send() Befehl absetzt, wird seine Ausführung angehalten. Dieser Zustand bleibt solange erhalten, bis er auf seine versendete Nachricht eine Antwort erhält. Dadurch wird sichergestellt, daß die Verarbeitung einer Aufgabe, von Prozeß B für Prozeß A, fertig ist, bevor Prozeß A seine Ausführung wieder aufnimmt. Weiter kann Prozeß B, sobald er seinen Receive() Befehl abgesetzt hat, seine Ausführung solange nicht fortführen, bis er eine weitere Nachricht erhält.
| Für weitere Informationen, wie QNX Prozesse einteilt, lesen Sie bitte ``Prozeß-Scheduling'' in diesem Kapitel. |
Prozeßzustände
Wenn ein Prozeß seine Ausführung nicht fortsetzen darf - da er auf die Beendigung von Teilen des Nachrichtenprotokolles warten muß - bezeichnet man den Prozeß als blockiert.
Die folgende Tabelle stellt die entsprechenden Zustände von Prozessen dar:
| Wenn ein Prozeß: | Ist der Prozeß: |
|---|---|
| einen Send() Befehl absetzt, und die versandte Nachricht wurde von dem Empfängerprozeß noch nicht entgegengenommen | SEND-blockiert |
| einen Send() Befehl absetzt, und die Nachricht wurde von dem Empfängerprozeß entgegengenommen aber noch nicht beantwortet | REPLY-blockiert |
| einen Receive() Befehl absetzt, bisher aber noch keine Nachricht empfangen hat | RECEIVE-blockiert |
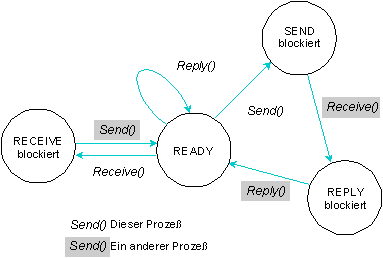
Ein Prozeß durchläuft Zustandsänderungen in einer typischen ``Senden-Empfangen-Beantworten-Transaktion''.
| Für Informationen zu möglichen Prozeßzuständen lesen Sie Kapitel 3, ``Der Prozeß-Manager.'' |
Send(), Receive() und Reply()
Lassen Sie uns nun einmal die Send()-, Receive()- und Reply()-Funktionsaufrufe genauer betrachten. Wir bleiben bei unserem Beispiel von Prozeß A und Prozeß B.
Send()
Nehmen wir an, daß Prozeß A eine Anfrage absetzt, um an Prozeß B eine Nachricht zu verschicken. Er initiiert diese Anfrage durch einen Aufruf von Send():
Send( pid, smsg, rmsg, smsg_len, rmsg_len );
Der Send() Aufruf enthält folgende Argumente:
- pid
- die Prozeß ID des Prozesses, der die Nachricht empfangen soll (z. B. Prozeß B); eine pid identifiziert den Prozeß eindeutig im Betriebssystem und unterscheidet ihn von anderen Prozessen
- smsg
- der Nachrichtenpuffer (z. B. die zu versendende Nachricht)
- rmsg
- der Antwortpuffer (er enthält später die Antwort von Prozeß B)
- smsg_len
- die Länge der versendeten Nachricht
- rmsg_len
- die maximale Länge der Antwortnachricht, die von Prozeß A akzeptiert wird
Beachten Sie, daß nicht mehr als mit smsg_len festgelegte Bytes gesendet werden und nicht mehr als in rmsg_len Bytes in der Antwort akzeptiert werden - dadurch wird sichergestellt, daß Puffer nicht ungewollt überschrieben werden.
Receive()
Prozeß B empfängt das von Prozeß A abgesetzte Send(), indem er einen Receive() Befehl absetzt:
pid = Receive( 0, msg, msg_len );
Der Receive() Aufruf enthält die folgenden Argumente:
- pid
- die Prozeß ID des sendenden Prozesses (z. B. Prozeß A) wird zurückgegeben
- 0
- (zero, Null) gibt an, daß Prozeß B bereit ist, eine Nachricht von jedem Prozeß zu empfangen
- msg
- Der Puffer, in dem die Nachricht empfangen wird
- msg_len
- die maximale Datenlänge, die im Empfangspuffer akzeptiert wird
Differieren smsg_len in dem Send() Aufruf und msg_len in dem Receive() Aufruf in Ihrer Größe, bestimmt der kleinere von beiden Werten die zu transportierende Datenmenge.
Reply()
Sobald Prozeß B erfolgreich die Nachricht von Prozeß A empfangen hat, sollte er Prozeß A antworten, indem er einen Reply() Funktionsaufruf absetzt:
Reply( pid, reply, reply_len );
Der Reply() Aufruf enthält folgende Argumente:
- pid
- die Prozeß ID des Prozesses, welcher die Antwort erhalten soll (z.B. Prozeß A)
- reply
- der Antwortpuffer
- reply_len
- die Länge der Daten, welche in der Antwort übermittelt werden
Wenn sich der Wert in reply_len beim Reply() Aufruf und der Wert in rmsg_len beim Send() Aufruf in der Größe unterscheiden, bestimmt der kleinere Wert von beiden, wieviele Daten verschickt werden.
Antwortgetriebene Kommunikation
Das Nachrichtenbeispiel, auf welches wir uns soeben bezogen haben, illustriert den häufigsten Gebrauch von Nachrichten - bei dem ein Serverprozeß normalerweise für eine Anfrage eines Client RECEIVE-blockiert ist. Dieses nennt man sendegetriebene Kommunikation (send-driven messaging): der Clientprozeß initiiert die Aktion, indem er eine Nachricht versendet, und die Aktion wird durch den Server beendet, indem er auf die Nachricht antwortet.
Nicht so häufig wie die sendegetriebene Kommunikation - aber oftmals wünschenswert - ist die antwortgetriebene Kommunikation, in welcher die Aktion mit einem Reply() initiiert wird. In dieser Methode sendet ein ``Arbeiter''-Prozeß eine Nachricht an den Server, in der er seine Bereitschaft zu arbeiten signalisiert. Der Server antwortet nicht sofort, wird sich aber ``merken'', daß der Arbeiter-Prozeß seine Bereitschaft bekannt gegeben hat. Zu einem späteren Zeitpunkt könnte sich der Server dazu entschließen, eine Aktion zu initiieren, indem er dem verfügbaren Arbeiterprozeß antwortet. Der Arbeiterprozeß wird die Arbeit verrichten und dann die Aktion beenden, indem er eine Nachricht mit den Ergebnissen an den Server sendet.
Wichtige Punkte zur Erinnerung
Hier noch ein paar Punkte, die man beim Nachrichtenaustausch (Message Passing) wissen sollte:
- Die Nachrichtendaten verbleiben solange in dem sendenden Prozeß bis der Empfänger bereit ist, die Nachricht zu verarbeiten. Es wird keine Kopie der Nachricht im Mikrokernel hinterlegt. Das ist deshalb sicher, da der sendende Prozeß SEND-blockiert und nicht in der Lage ist, unbeabsichtigt die Nachricht zu modifizieren.
- Die Daten der Antwortnachricht werden von dem antwortenden Prozeß zu dem REPLY-blockierten Prozeß in Form einer atomaren Operation kopiert, sobald die Reply() Anfrage abgesetzt wird. Das Reply() blockiert den antwortenden Prozeß nicht - der REPLY-blockierte Prozeß wird in den Zustand READY gesetzt, sobald die Daten in seinen Adressraum kopiert werden.
- Der sendende Prozeß muß über den Zustand des empfangenden Prozesses vor Absenden einer Nachricht nicht informiert sein. Wenn der empfangende Prozeß noch nicht auf den Empfang einer Nachricht vorbereitet ist, wird der sendende Prozeß lediglich SEND-blockiert.
- Wenn nötig, kann die Länge einer Nachricht beim Senden, Antworten oder bei beiden Null Bytes betragen.
- Aus der Sicht des Entwicklers ist das Absetzen eines Send() an einen Serverprozeß, um einen Dienst zu erhalten, virtuell identisch mit dem Aufrufen einer Bibliotheksfunktion, um den gleichen Dienst zu erhalten. In beiden Fällen initialisieren Sie erst einige Datenstrukturen, und rufen dann Send() oder die Bibliotheksfunktion auf. Der gesamte Dienstcode zwischen zwei wohldefinierten Punkten - Receive() und Reply() für einen Serverprozeß, Funktionseintritt und returnStatement für einen Bibliotheksaufruf - wird dann ausgeführt, während Ihr Code wartet. Wenn der Dienstaufruf zurückkehrt, ``weiß'' Ihr Code, wo Ergebnisse aufbewahrt werden und kann die Suche nach Fehlerkonditionen, Prozeßergebnissen oder was auch immer, fortsetzen.
Neben dieser scheinbaren Einfachheit macht der Code aber viel mehr als nur einen einfachen Bibliotheksaufruf. Das Send() kann transparent über das Netzwerk zu einer anderen Maschine gelangen, auf der der aktuelle Dienstcode gerade ausgeführt wird. Es kann auf diese Weise parallele Verarbeitung ermöglichen, ohne den Overhead für das Erzeugen von neuen Prozessen zu haben. Der Serverprozeß kann ein Reply() absetzen und dem Rufenden erlauben, seine Ausführung, sobald es sicher ist, fortzuführen und währenddessen seine eigene Ausführung fortsetzen.
- Es können Nachrichten von vielen Prozessen für einen einzelnen empfangenden Prozeß anstehen. Normalerweise empfängt ein Prozeß die Nachrichten in der Reihenfolge, in der sie von anderen Prozessen abgesetzt wurden; der empfangende Prozeß kann festlegen, daß er die Nachrichten in der Reihenfolge empfängt, die den Prioritäten der sendenden Prozesse entspricht.
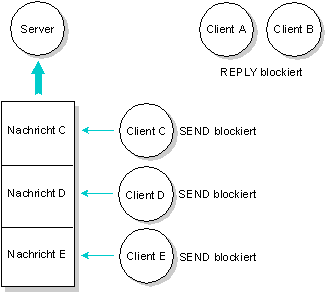
Der Server hat Nachrichten von Client A und Client B empfangen (aber noch nicht beantwortet). Der Server hat von den Clients C, D und E noch keine Nachrichten empfangen.
Komfortable Erweiterungen
QNX unterstützt zusätzlich die folgenden Varianten für den Nachrichtenaustausch:
- bedingter Nachrichtenempfang
- Lesen oder Schreiben einer Nachricht in Teilen
- Nachrichten aus vielen Teilen (multipart messages)
Bedingter Nachrichtenempfang
Wenn ein Prozeß eine Nachricht empfangen möchte, benutzt er Receive(). Das ist der normale Weg, um Nachrichten zu empfangen und in den meisten Fällen angemessen.
In manchen Fällen ist es für einen empfangenden Prozeß sinnvoll nachzusehen, ob Nachrichten für den Empfang warten, ohne daß er in den RECEIVE-blockierten Zustand versetzt wird, für den Fall, daß keine Nachrichten vorhanden sind. Ist zum Beispiel ein Gerät nicht in der Lage Interrupts zu generieren, so muß ein Prozeß zyklisch nachschauen, ob das Gerät einen Service benötigt. Will der Prozeß jedoch weiterhin Nachrichten von anderen Prozessen empfangen, muß es ein geeignetes Werkzeug hierfür geben. Dem Prozeß steht die Funktion Creceive() zur Verfügung mit der man prüfen kann, ob Nachrichten anstehen. Sind keine Nachrichten vorhanden, kehrt die Funktion unmittelbar zurück.
| Sie sollten, wenn möglich, die Creceive() Funktion vermeiden, da sie es einem Prozeß erlaubt, die Prozessorkapazität auf seinem Prioritätslevel vollständig zu konsumieren. |
Lesen oder Schreiben von Teilen einer Nachricht
Manchmal mag es wünschenswert sein, nur Teile einer Nachricht zu lesen oder zu schreiben, so daß Sie den Pufferplatz, der der Nachricht zugeordnet ist, nutzen, anstatt einen separaten Arbeitspuffer zu belegen.
Ein I/O-Manager kann vielleicht Nachrichten akzeptieren, deren Daten einen Header mit fester Größe enthalten, welchem eine variable Datenmenge folgen kann. Der Header enthält die Byteangabe der Daten (0 bis 64K Bytes). Der I/O-Manager kann wählen, nur den Header zu empfangen und nachfolgend die Readmsg() Funktion benutzen, um die variable Datenmenge direkt in einen entsprechenden Ausgabepuffer zu transferieren. Wenn die gesendeten Daten die Puffergröße des I/O-Managers überschreiten, kann der Manager im Laufe der Zeit verschiedene Readmsg() Anfragen absetzen, um die Daten dann zu transportieren, wenn Platz verfügbar wird. Gleichermaßen kann die Writemsg() Funktion benutzt werden, um Daten im Laufe der Zeit anzusammeln, um diese in den Antwortpuffer des Senders zu kopieren, sobald dieser verfügbar wird. Dies reduziert die Anforderungen des I/O-Managers an interne Puffergrößen.
Mehrteilige Nachrichten
Bisher wurden einzelne Nachrichten als einzelne Bytepakete betrachtet. Oftmals bestehen Nachrichten aber aus zwei oder mehr Komponenten. Eine Nachricht kann zum Beispiel einen Header von festgesetzter Größe beinhalten, gefolgt von einer variablen Menge an Daten. Um sicherzustellen, daß ihre Komponenten effizient versendet oder empfangen werden, ohne sie in einen temporären Arbeitspuffer zu kopieren, kann eine mehrteilige Nachricht aus zwei oder mehr separaten Nachrichtenpuffern konstruiert werden. Diese Möglichkeit hilft den QNX I/O-Managern, wie dem Dev und Fsys, ihre hohe Performance zu erhalten.
Die folgenden Funktionen stehen für die Bearbeitung mehrteiliger Nachrichten zur Verfügung:
- Creceivemx()
- Readmsgmx()
- Receivemx()
- Replymx()
- Sendmx()
- Writemsgmx()
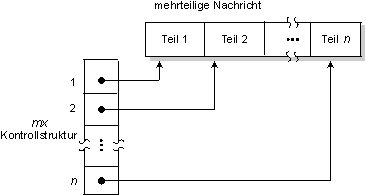
Mehrteilige Nachrichten können mit einer mx-Kontrollstruktur definiert werden. Der Mikrokernel verbindet diese bei der Übermittlung zu einem einzigen kontinuierlichen Datenstrom.
Reservierte Nachrichtencodes
Obwohl es nicht zwingend erforderlich ist, beginnt QNX alle seine Nachrichten mit einem 16-Bit Wort, ein Nachrichtencode (message code) genannt. Beachten Sie, daß QNX Systemprozesse Nachrichtencodes mit den folgenden Bereichen verwendet:
| Reservierter Bereich: | Beschreibung: |
|---|---|
| 0x0000 bis 0x00FF | Prozeß-Manager-Nachrichten |
| 0x0100 bis 0x01FF | I/O-Nachrichten (für alle I/O-Server gleich) |
| 0x0200 bis 0x02FF | Dateisystem-Manager-Nachrichten |
| 0x0300 bis 0x03FF | Geräte-Manager-Nachrichten |
| 0x0400 bis 0x04FF | Netzwerk-Manager-Nachrichten |
| 0x0500 bis 0x0FFF | reserviert für zukünftige QNX-Systemprozesse |
IPC über Proxies
Eine Proxy ist eine Form von nicht-blockierenden Nachrichten. Sie wird besonders dann benutzt, wenn der sendende Prozeß mit dem Empfänger nicht interagieren muß. Die einzige Funktion einer Proxy ist es, eine feste Nachricht an einen spezifischen Prozeß zu senden, welchem die Proxy gehört. Wie Nachrichten, arbeiten Proxies auch über das Netzwerk.
Durch den Gebrauch einer Proxy, kann ein Prozeß oder ein Interrupthandler eine Nachricht an einen anderen Prozeß senden, ohne zu blockieren oder auf eine Antwort warten zu müssen.
Hier einige Beispiele für den Einsatz von Proxies:
- Ein Prozeß möchte einem anderen Prozeß mitteilen, daß ein Ereignis eingetreten ist, kann es sich aber nicht leisten, eine Nachricht zu schicken (das würde ihn solange blockieren, bis der Empfänger ein Receive() und ein Reply() absetzt).
- Ein Prozeß möchte Daten zu einem anderen Prozeß schicken, benötigt aber weder eine Antwort noch irgend eine andere Bestätigung, daß der Empfänger die Nachricht erhalten hat.
- Ein Interrupthandler möchte einem Prozeß mitteilen, daß Daten für die Verarbeitung verfügbar sind.
Proxies werden mit der qnx_proxy_attach() Funktion erzeugt. Jeder andere Prozeß oder Interrupthandler, der die Identität der Proxy kennt, kann dann diese dazu veranlassen, ihre vordefinierte Nachricht mit der Trigger() Funktion auszuliefern, welche vom Mikrokernel ausgeliefert wird.
Eine Proxy kann mehr als einmal ausgelöst (getriggert) werden - jedesmal wenn sie ausgelöst wird, sendet sie eine Nachricht. Ein Proxyprozeß kann bis zu 65.535 Triggerbefehle aufnehmen, um die Nachricht auszuliefern.
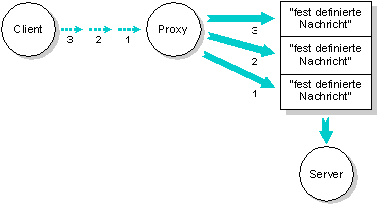
Ein Clientprozeß löst eine Proxy dreimal aus. Dadurch wird der Server veranlaßt, drei ``fest definierte'' Nachrichten von der Proxy zu empfangen.
IPC über Signale
Signale sind eine traditionelle Methode der asynchronen Kommunikation, welche seit vielen Jahren in unterschiedlichsten Betriebssystemen verfügbar sind.
QNX unterstützt einen großen Satz POSIX-konformer Signale, einige historische UNIX-Signale sowie einige QNX-spezifische Signale.
Signale generieren
Ein Signal wird dann an einen Prozeß ausgeliefert, wenn die vom Prozeß definierte Aktion für dieses Signal eintritt. Ein Prozeß kann auch ein Signal an sich selbst schicken.
| Wenn Sie möchten, daß: | Benutzen Sie: |
|---|---|
| ein Signal aus der Shell erzeugt wird | die kill oder slay Werkzeuge |
| ein Signal aus einem Prozeß heraus generiert wird | die kill() oder raise() C Funktionen |
Signale empfangen
Ein Prozeß kann ein Signal in einer von drei Arten empfangen, abhängig davon, wie er seine Umgebung für den Umgang mit Signalen definiert hat:
- Wenn der Prozeß keine spezielle Aktion für den Umgang mit Signalen vorgesehen hat, wird die Standardaktion für das Signal ausgeführt - diese Aktion wird normalerweise den Prozeß beenden.
- Der Prozeß kann das Signal ignorieren. Wenn ein Prozeß ein Signal ignoriert, hat die Auslieferung des Signales keinen Einfluß auf den Prozeß (beachten Sie, daß die SIGCONT, SIGKILL und SIGSTOP Signale unter normalen Umständen nicht ignoriert werden können).
- Der Prozeß kann für das Signal einen Signalhandler installieren - ein Signalhandler ist eine Funktion in dem Prozeß, welche aufgerufen wird, sobald das Signal ausgeliefert ist. Wenn ein Prozeß einen Signalhandler für ein Signal installiert hat, ist er in der Lage, das Signal zu ``empfangen''. Jeder Prozeß, der ein Signal empfängt, erhält eine Art Softwareinterrupt. Mit dem Signal werden keine Daten transferiert.
Während der Zeit zwischen Generierung und Auslieferung eines Signales bezeichnet man das Signal als ``anstehend''. Viele verschiedene Signale können zur gleichen Zeit für einen Prozeß anstehen. Signale werden an einen Prozeß ausgeliefert, wenn der Prozeß durch den Scheduler des Mikrokernel lauffähig gemacht wird. Ein Prozeß sollte sich nicht darauf verlassen, daß Signale in einer bestimmten Reihenfolge an ihn ausgeliefert werden.
Liste der Signale
| Signal: | Beschreibung: |
|---|---|
| SIGABRT | Abnormales Beendigungssignal, wie durch die abort() Funktion ausgeliefert. |
| SIGALRM | Timeout Signal, wie durch die alarm() Funktion ausgeliefert. |
| SIGBUS | Deutet einen Speicherparitätsfehler an (QNX-spezifische Interpretation). Beachten Sie, daß der Prozeß, wenn ein weiterer Fehler auftritt, während er sich in einem Signalhandler für den ersten Fehler befindet, beendet wird. |
| SIGCHLD | Ein Sohnprozeß (Child) wird beendet. Die Standardaktion ist, das Signal zu ignorieren. |
| SIGCONT | Prozeß fährt fort, wenn er im Zustand HELD ist. Die Standardaktion ist, das Signal zu ignorieren, wenn der Prozeß nicht HELD ist. |
| SIGDEV | Wird generiert, wenn ein signifikantes und angefordertes Ereignis im Geräte-Manager auftritt. |
| SIGFPE | Fehlerhafte arithmetische Operation (Integer oder Floating Point), wie das Teilen durch Null oder eine Operation, die in einem Überlauf endet. Beachten Sie, daß der Prozeß, wenn ein weiterer Fehler auftritt während er sich in einem Signalhandler für den ersten Fehler befindet, beendet wird. |
| SIGHUP | Beendigung des ``session leader'' oder ``hangup-Bedingung'' am kontrollierenden Terminal. |
| SIGILL | Feststellung einer ungültigen Hardwareinstruktion. Beachten Sie, daß der Prozeß, wenn ein weiterer Fehler auftritt während er sich in einem Signalhandler für den ersten Fehler befindet, beendet wird. |
| SIGINT | Interaktives Aufmerksamkeitssignal (Break) |
| SIGKILL | Beendigungssignal - sollte nur in Notfällen benutzt werden. Dieses Signal kann weder aufgefangen noch ignoriert werden. Beachten Sie, daß sich ein Server mit Superuser Privilegien gegen dieses Signal mit der qnx_pflags() Funktion schützen kann. |
| SIGPIPE | Versuch, in eine Pipe ohne angeschlossenen Leser zu schreiben. |
| SIGPWR | Softboot Anfrage über Ctrl-Alt-Shift-Del oder das shutdown Werkzeug. |
| SIGQUIT | Interaktives Beendigungssignal. |
| SIGSEGV | Entdeckung einer ungültigen Speicherreferenz. Beachten Sie, daß der Prozeß, wenn ein weiterer Fehler auftritt während er sich in einem Signalhandler für den ersten Fehler befindet, beendet wird. |
| SIGSTOP | HOLD Prozeßsignal. Die Standardaktion ist, den Prozeß anzuhalten. Beachten Sie, daß sich ein Server mit Superuser Privilegien gegen dieses Signal mit der qnx_pflags() Funktion schützen kann. |
| SIGTERM | Beendigungssignal |
| SIGTSTP | Wird von QNX nicht unterstützt. |
| SIGTTIN | Wird von QNX nicht unterstützt. |
| SIGTTOU | Wird von QNX nicht unterstützt. |
| SIGUSR1 | Reserviert als anwendungsdefiniertes Signal 1 |
| SIGUSR2 | Reserviert als anwendungsdefiniertes Signal 2 |
| SIGWINCH | Die Fenstergröße wurde verändert |
Signalbearbeitung einrichten
Um den Typ der Verarbeitung für jedes Signal zu definieren, benutzen Sie die ANSI C signal() Funktion oder die POSIX sigaction() Funktion.
Die sigaction() Funktion gibt Ihnen eine größere Kontrolle über die signalverarbeitende Umgebung.
Den Verarbeitungstyp für ein Signal können Sie jederzeit ändern. Wenn Sie die Signalverarbeitung für eine Funktion auf ignorieren setzen, werden alle anstehenden Signale dieser Art unverzüglich gelöscht.
Signale empfangen
Einige spezielle Überlegungen sind für Prozesse zu machen, welche Signale mit einer signalverarbeitenden Funktion empfangen wollen.
Die signalverarbeitende Funktion ist einem Softwareinterrupt gleichzusetzen. Sie wird zu dem Rest des Prozesses asynchron ausgeführt. Deshalb ist es möglich, einen Signalhandler auszuführen, während sich der Prozessor in irgendeiner Funktion in dem Programm befindet (einschließlich Bibliotheksfunktionen).
Wenn Ihr Prozeß von dem Signalhandler nicht zurückkehrt, kann er entweder siglongjmp() oder longjmp() benutzen, wobei siglongjmp() bevorzugt wird. Wird longjmp() benutzt, bleibt das Signal blockiert.
Signale blockieren
Manchmal möchten Sie vielleicht zeitweise verhindern, daß ein Signal ausgeliefert wird, ohne die Methode, wie das Signal verarbeitet wird, zu ändern. QNX bietet eine Reihe von Funktionen, mit welchen man die Auslieferung von Signalen blockieren kann. Ein blockiertes Signal bleibt anstehend. Wird die Blockierung aufgehoben, wird es an Ihr Programm ausgeliefert.
Während Ihr Prozeß einen Signalhandler für ein bestimmtes Signal ausführt, blockiert QNX automatisch dieses Signal. Das bedeutet, daß Sie sich nicht darum sorgen müssen, wiederholte Aufrufe Ihres Signalhandlers innerhalb desselben einzurichten. Jeder Aufruf Ihres Signalhandlers ist eine atomare Operation mit Rücksicht auf die Auslieferung weiterer Signale gleichen Typs. Kehrt Ihr Prozeß normal von dem Handler zurück, wird die Blockierung für dieses Signal automatisch aufgehoben.
| Einige UNIX-Systeme haben eine fehlerhafte Implementation von Signalhandlern, da sie das Signal auf die Standardaktion zurücksetzen anstatt das Signal zu blockieren. Daraus resultierend rufen einige UNIX- Applikationen die signal() Funktion innerhalb des Signalhandlers auf, um den Handler wiederholt zu installieren. Dies läßt zwei Fehlerlücken entstehen. Erstens, wenn ein anderes Signal ankommt, während sich Ihr Programm noch im Handler befindet, signal() aber noch nicht erneut aufgerufen wurde, könnte Ihr Programm beendet werden. Zweitens, wenn ein Signal unverzüglich nach dem Aufruf von signal() in dem Handler ankommt, würde der Handler rekursiv ausgeführt. QNX unterstützt die Blockierung von Signalen und vermeidet deshalb diese Probleme. Sie müssen signal() nicht in Ihrem Handler aufrufen. Wenn Sie Ihren Handler über einen long jump verlassen, sollten Sie die siglongjmp() Funktion benutzen. |
Signale und Nachrichten
Es gibt eine wichtige Interaktion zwischen Signalen und Nachrichten. Ist Ihr Prozeß SEND- oder RECEIVE-blockiert wenn ein Signal generiert wird - und Sie haben einen Signalhandler installiert - werden die folgenden Aktionen ausgeführt:
- Die Prozeßblockierung wird aufgehoben.
- Die Signalbearbeitung beginnt
- Das Send() oder Receive() gibt einen Fehler zurück
War Ihr Prozeß zu diesem Zeitpunkt SEND-blockiert, ergibt sich hieraus kein Problem, weil der Empfänger keine Nachricht erhalten hätte. War Ihr Prozeß aber REPLY-blockiert, würden Sie nicht wissen, ob die gesendete Nachricht verarbeitet wurde und somit wüßten Sie auch nicht, ob Sie das Send() wiederholen müssen.
Es ist einem Prozeß, der sich wie ein Server verhält (er empfängt z. B. Nachrichten) möglich, darum zu bitten, ihn zu benachrichtigen, wenn an einen REPLY-blockierten Clientprozeß Signale gesendet werden. In diesem Fall wird der Clientprozeß mit einem anstehenden Signal auf SIGNAL-blockiert gesetzt, und der Serverprozeß empfängt eine spezielle Nachricht, welche den Typ des Signales beschreibt. Der Serverprozeß kann sich dann für eine der folgenden Möglichkeiten entscheiden:
- Die Originalanfrage normal beenden - dem Sender wird versichert, daß die Nachricht korrekt verarbeitet wurde.
ODER
- Freigeben aller für den Clientenprozeß belegten Ressourcen und einen Fehler zurückgeben, welcher aussagt, daß die Prozeßblockade durch ein Signal aufgehoben wurde - der Sender erhält eine klare Fehleranzeige.
Wenn der Server einem SIGNAL-blockierten Prozeß antwortet, wird das Signal unverzüglich nach der Rückkehr des Send() von dem Sender eintreten.
IPC über das Netzwerk
Virtuelle Verbindungen
Eine QNX Applikation kann mit einem Prozeß auf einer anderen Maschine im Netzwerk genauso kommunizieren, als ob er mit einem anderen Prozeß auf der gleichen Maschine kommuniziert. Tatsächlich gibt es aus der Sicht der Applikation keinen Unterschied zwischen lokalen und entfernten Ressourcen.
Dieser bemerkenswerte Grad an Transparenz wird durch virtuelle Verbindungen (VCs) ermöglicht, welche Pfade sind, die der Netzwerk-Manager für die Überbringung von Nachrichten, Proxies und Signalen über das Netzwerk, anbietet.
VCs tragen zu einem effizienten, allumfassenden Gebrauch von Ressourcen in einem QNX Netzwerk aus vielen Gründen bei:
- Wenn ein VC erzeugt wird, kann er Nachrichten einer angegebenen Größe verarbeiten; das bedeutet, daß Sie Ressourcen von vorneherein zur Verarbeitung der Nachrichten anfordern können. Für den Fall, daß die Nachricht größer ist als die angegebene Größe des VCs, erfolgt eine automatische Anpassung.
- Wenn zwei auf unterschiedlichen Knoten liegende Prozesse miteinander über mehr als einen VC kommunizieren, werden die VCs gemeinsam benutzt - es existiert nur eine echte virtuelle Verbindung zwischen den Prozessen. Diese Situation ergibt sich im Allgemeinen, wenn ein Prozeß auf viele Dateien eines entfernten Dateisystems zugreift.
- Verbindet sich ein Prozeß mit einem existierenden gemeinsam genutzten VC und er erwartet einen größeren Puffer als den aktuell genutzten, wird dessen Größe automatisch angepasst.
- Beendet sich ein Prozeß, werden die von ihm benutzten VCs automatisch freigegeben.
Virtuelle Prozesse
Ein sendender Prozeß ist für die Einrichtung des VC zwischen sich und dem Prozeß, mit dem er kommunizieren möchte, verantwortlich. Um dies zu erreichen, setzt der sendende Prozeß normalerweise einen qnx_vc_attach() Funktionsaufruf ab. Zusätzlich zur Erzeugung eines VCs, erzeugt dieser Aufruf an jedem Ende der Verbindung ebenfalls eine virtuelle Prozeß ID, bzw. VID. Dem Prozeß an jeder Seite der virtuellen Verbindung erscheint die VID an seinem Ende als ob sie die Prozeß ID des entfernten Prozesses, mit dem er kommunizieren möchte, wäre. Prozesse kommunizieren dann über diese VIDs miteinander.
In der folgenden Illustration verbindet zum Beispiel eine virtuelle Verbindung PID 1 mit PID 2. Auf Knoten 20 - wo PID 1 liegt - repräsentiert ein VID PID 2. Auf Knoten 40 - wo PID 2 liegt - repräsentiert ein VID PID 1. Sowohl PID 1 als auch PID 2 können sich auf das VID auf ihrem Knoten beziehen, als ob es irgendein anderer lokaler Prozeß wäre (Nachrichten senden, Nachrichten empfangen, Signale absetzen, warten, etc.). So kann zum Beispiel PID 1 eine Nachricht an die VID an seinem Ende schicken. Diese VID wird dann die Nachricht über das Netzwerk an die VID von PID 1 am anderen Ende übertragen. Diese VID, die PID 1 representiert, wird die Nachricht dann an PID 2 ausliefern.
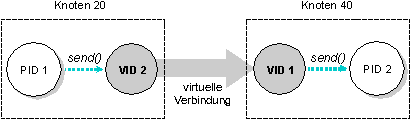
Netzwerkkommunikation wird durch virtuelle Verbindungen ermöglicht. Wenn PID 1 an VID 2 sendet, wird die Sendeanforderung über das Netzwerk an VID 1 gesendet, welches die Nachricht an PID 2 ausliefert.
Jede VID hält eine Verbindung aufrecht, welche die folgenden Informationen pflegt:
- lokales pid
- entferntes pid
- entferntes nid (Knoten (node) ID)
- entferntes vid
Möglicherweise werden Sie nicht sehr oft in direkten Kontakt mit VCs kommen. Wenn beispielsweise eine Applikation auf eine I/O-Ressource über das Netzwerk zugreifen möchte, wird ein VC durch eine open() Bibliotheksfunktion im Auftrag der Applikation erzeugt. Die Applikation hat keinen direkten Anteil an der Erzeugung oder Nutzung des VC. Wenn eine Applikation den Standort eines Servers mit qnx_name_locate() ermittelt, wird automatisch im Auftrag der Applikation ein VC erzeugt. Der Appliaktion erscheint das VC lediglich wie eine PID.
Zu mehr Informationen über qnx_name_locate(), lesen Sie die Abhandlung über symbolische Prozeßnamen in Kapitel 3.
Virtuelle Proxies
Eine virtuelle Proxy erlaubt es, eine Proxy von einem entfernten Knoten aus anzusprechen, fast wie es eine virtuelle Verbindung einem Prozeß erlaubt, Nachrichten mit einem entfernten Knoten auszutauschen.
Im Gegensatz zu einer virtuellen Verbindung, welche zwei Prozesse miteinander verbindet, erlaubt eine virtuelle Proxy jedem Prozeß auf dem entfernten Knoten, diese zu triggern.
Virtuelle Proxies werden von qnx_proxy_rem_attach() erzeugt, der einen Knoten (nid_t) und eine Proxy (pid_t) als Argumente übergeben werden. Eine virtuelle Proxy wird auf dem entfernten Knoten erzeugt, wobei sie sich auf den Knoten des Aufrufers bezieht.
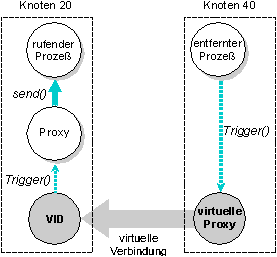
Eine virtuelle Proxy wird auf dem entfernten Knoten, welcher sich auf die Proxy des rufenden Knotens bezieht, erzeugt.
Beachten Sie, daß die virtuelle Verbindung automatisch auf dem Knoten des rufenden Prozesses durch qnx_proxy_rem_attach() erzeugt wird.
Beendigung virtueller Verbindungen
Manchmal wird es für einen Prozeß unmöglich, über eine eingerichtete VC mit dem Partnerprozeß zu kommunizieren. Die Gründe hierfür können sein:
- Der Computer, auf dem er lief, wird ausgeschaltet.
- Das Netzwerkkabel zum Compter wurde unterbrochen.
- Der entfernte Prozeß, mit dem er kommunizierte, wurde beendet.
Alle diese Bedingungen können die Auslieferung von Nachrichten über eine VC verhindern. Es ist notwendig diese Situationen zu erkennen, so daß Applikationen entsprechende Aktionen einleiten oder sich selbst sinnvoll beenden können. Geschieht dies nicht, ist es möglich, daß Ressourcen belegt bleiben und anderen Prozessen nicht mehr zur Verfügung stehen.
Der Prozeß-Manager auf jedem Knoten prüft die Integrität der VCs auf seinem Knoten. Dies geschieht durch folgende Schritte:
- Jedesmal, wenn eine erfolgreiche Übermittlung auf einem VC stattfindet, wird ein mit dem VC verbundener Zeitstempel aktualisiert, um den Zeitpunkt der letzten Aktivität festzuhalten.
- Der Prozeß-Manager schaut in definierbaren Intervallen auf jedes VC. Hat es auf einer Verbindung keine Aktivitäten gegeben, sendet der Prozeß-Manager ein Netzwerkintegritätspaket an den Prozeß-Manager auf dem Knoten am anderen Ende der Verbindung.
- Kommt keine Antwort zurück oder es wird ein Problem angedeutet, wird das VC entsprechend gekennzeichnet. Daraufhin wird eine definierte Anzahl von Versuchen gestartet, um den Kontakt wieder herzustellen.
- Schlägt der Versuch fehl, wird die VC aufgelöst und alle hierauf blockierten Prozesse werden READY gesetzt. (Der Prozeß erkennt den Fehler der Kommunikation durch den Rückgabewert der Kommunikationsfunktion.)
Die Parameter für die Integritätskontrolle werden mit dem netpoll Werkzeug eingestellt.
IPC über Semaphoren
Eine andere Form der Prozeßsynchronisation sind Semaphoren. Prozessen ist es möglich, eine Semaphore "zu posten" (sem_post()) und "anzufragen" (sem_wait()), um ihren Zustand zu verändern. Die Postoperation inkrementiert die Semaphore; die Waitoperation dekrementiert sie.
Warten Sie auf eine positive Semaphore, wird Ihr Prozeß nicht blockiert. Das Warten auf eine nicht-positive Semaphore wirkt solange blockierend, bis ein anderer Prozeß auf diese Semaphore ein post ausführt. Es ist zulässig, ein oder mehrmals vor einem wait zu posten - dadurch wird es einem oder mehreren Prozessen möglich, das wait auszuführen ohne zu blockieren.
Ein signifikanter Unterschied zwischen Semaphoren und anderen Synchronisationsfunktionen ist, daß Semaphoren "asynchron sicher" (async safe) sind, und durch Signalhandler manipuliert werden können. Wenn Sie wollen, daß ein Signalhandler einen Prozeß aufweckt, sind Semaphoren die richtige Wahl.
Prozeß-Scheduling
Wann Entscheidungen zum Ablaufplan getroffen werden
Der Scheduler des Mikrokernel entscheidet über den Ablaufplan, wenn:
- eine Prozeßblockierung aufgehoben wird
- die Zeitscheibe für einen laufenden Prozeß abläuft
- ein laufender Prozeß verdrängt wird
Prozeßprioritäten
In QNX wird jedem Prozeß eine Priorität zugeordnet. Der Scheduler entscheidet, welcher Prozeß als nächster läuft, indem er sich die Priorität aller Prozesse, welche READY sind, ansieht (ein Prozeß im Zustand READY ist in der Lage, die CPU zu nutzen). Der Prozeß mit der höchsten Priorität wird gewählt.
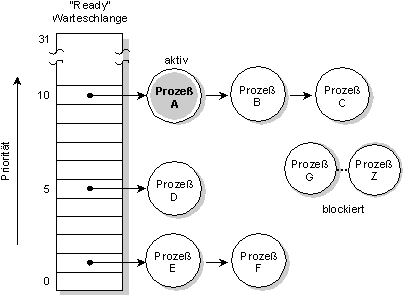
Die Warteschlange für Prozesse (A-F) mit dem Zustand READY. Alle anderen Prozesse (G-Z) sind im Zustand BLOCKED. Prozeß A läuft momentan. Die Prozesse A, B und C haben die höchste Priorität, so daß sie sich, basierend auf dem ihnen zugewiesenen Scheduling-Algorithmus, die CPU teilen.
Die Prioritäten von Prozessen liegen zwischen 0 (der kleinsten) und 31 (der höchsten). Die Standardpriorität eines neuen Prozesses wird ihm von seinem Vaterprozeß vererbt. Normalerweise wird sie für Applikationen, welche von der Shell gestartet werden, auf 10 gesetzt.
| Wenn Sie: | Benutzen Sie diese Funktion: |
|---|---|
| Die Priorität eines Prozesses erfragen möchten | getprio() |
| Die Priorität eines Prozesses setzen möchten | setprio() |
Scheduling-Methoden
Um die Anforderungen verschiedener Applikationen zu befriedigen, bietet QNX drei Methoden für das Scheduling:
- FIFO-Scheduling
- Round-Robin-Scheduling
- adaptives Scheduling
Jeder Prozeß im System benutzt eine dieser drei Methoden. Das Scheduling-Verfahren bezieht sich immer auf einen Prozeß und nicht auf alle Prozesse eines Knotens. Scheduling-Verfahren arbeiten also prozeßbasierend.
Erinnern Sie sich, daß diese Scheduling-Methoden nur verwendet werden, wenn sich zwei oder mehr Prozessse von gleicher Priorität im READY-Zustand befinden (die Prozesse stehen zum Beispiel in direkter Konkurrenz zueinander). Gelangt ein Prozeß mit höherer Priorität in den Zustand READY, verdrängt er unverzüglich alle Prozesse mit niedrigerer Priorität, gleichgültig, welche Scheduling-Methode der verdrängte Prozeß hat.
Im folgenden Diagramm befinden sich drei Prozesse mit gleicher Priorität im READY Zustand. Blockiert Prozeß A, wird Prozeß B ausgeführt.
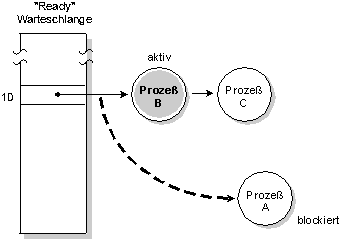
Prozeß A blockiert, Prozeß B läuft.
Obwohl ein Prozeß seine Scheduling-Methode von seinem Vaterprozeß erbt, kann diese Methode geändert werden.
| Wenn Sie: | Benutzen Sie diese Funktion: |
|---|---|
| Die Scheduling-Methode für einen Prozeß erfragen möchten | getscheduler() |
| Die Scheduling-Methode für einen Prozeß setzen möchten | setscheduler() |
FIFO-Scheduling
Bei der Methode FIFO-Scheduling setzt ein ausgewählter Prozeß seine Ausführung solange fort, bis er:
- die Ausführungskontrolle freiwillig abgibt (z.B. irgendeinen Kernelruf absetzt)
- durch einen Prozeß mit höherer Priorität verdrängt wird
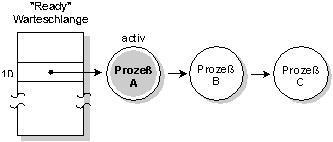
FIFO-Scheduling. Prozeß A läuft, bis er blockiert.
Zwei Prozesse, die die gleiche Priorität haben, können das FIFO- Scheduling benutzen, um einen gegensetigen Ausschluß eines Zugriffes auf eine von beiden genutzte Ressource, sicherzustellen. Keiner der Prozesse kann von dem anderen während seiner Ausführung verdrängt werden. Teilen sie sich zum Beispiel ein Speichersegment, kann jeder der zwei Prozesse das Segment aktualisieren, ohne auf eine Semaphore zurückgreifen zu müssen.
Round-Robin-Scheduling
Bei der Methode Round-Robin-Scheduling setzt ein ausgewählter Prozeß seine Ausführung solange fort, bis er:
- die Ausführungskontrolle freiwillig abgibt
- durch einen Prozeß mit höherer Priorität verdrängt wird
- seine Zeitscheibe abläuft
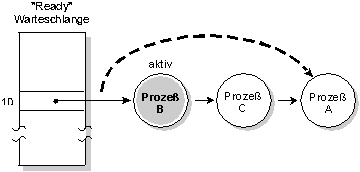
Round-Robin-Scheduling. Prozeß A lief, bis er seine Zeitscheibe aufbrauchte. Jetzt wird der nächste Prozeß mit dem Zustand READY (Prozeß B) ausgeführt.
Die Zeitscheibe ist eine Einheit, die jedem Prozeß zugewiesen wird. Wenn der Prozeß seine Zeitscheibe aufgebraucht hat, wird er verdrängt und der nächste laufwillige Prozeß mit dem Zustand READY und der gleichen Priorität wird zur Ausführung eingeplant. Eine Zeitscheibe beträgt 50 Millisekunden.
| Abgesehen von der Zeitscheibeneinteilung ist das Round-Robin-Scheduling identisch mit dem FIFO-Scheduling. |
Adaptives Scheduling
Beim adaptiven Scheduling verhält sich ein Prozeß wie folgt:
- Wenn ein Prozeß seine Zeitscheibe aufgebraucht hat (und er bis dahin nicht blockiert), wird seine Priorität um 1 verringert. Diesen Vorgang bezeichnet man als priority decay (Prioritätsverfall). Wichtig hierbei ist, daß die Verringerung nur um eine Prioritätsstufe erfolgt, auch wenn der Prozeß eine weitere Zeitscheibe verbraucht - die Priorität wird maximal um eins niedriger gesetzt, als die Ausgangspriorität.
- Blockiert ein Prozeß, bekommt er umgehend seine Ausgangspriorität zurück.
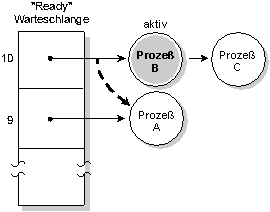
Adaptives Scheduling. Prozeß A verbraucht seine Zeitscheibe; seine Priorität wird um eins verringert. Der nächste Prozeß mit dem Zustand READY läuft (Prozeß B).
Vornehmlich wird das adaptive Scheduling in Umgebungen eingesetzt, bei denen sich rechenintensive Hintergrundprozesse die CPU mit interaktiven Anwendungen teilen müssen. Sie können beim adaptiven Scheduling erwarten, daß die rechenintensiven Prozesse genügend CPU-Leistung erhalten und die interaktiven Anwendungen gute Antwortzeiten haben.
Adaptives Scheduling ist der Standard für Programme, die über die Shell gestartet werden.
Clientgetriebene Priorität
Unter QNX folgen die meisten Transaktionen einem typischen Client/Server-Modell. Hierbei stellen Server einen Service bereit, den die Clients durch das Senden einer Nachricht anfordern.
Normalerweise gibt es mehr Client- als Serverprozesse. Dies bedeutet, daß ein Server meist mit höherer Priorität betrieben wird, als die anfragenden Clients. Die Schedulingmethode kann eine der drei zuvor beschriebenen sein, doch wird meist das Round-Robin-Verfahren benutzt.
Sendet ein Client mit niedriger Priorität eine Nachricht an den Server, wird diese vom Server mit der eigenen Serverpriorität bearbeitet. Die Auswirkung ist, daß die Priorität des Clients indirekt auf die Priorität des Servers angehoben wird, da der Server die Anfrage des Clients bearbeitet.
Wenn die Anfrage des Clients vom Server sehr schnell verarbeitet werden kann, fällt die hier auftretende Prioritäteninversion nicht sonderlich ins Gewicht. Sollte der Server für die Erledigung seiner Aufgabe jedoch mehr Zeit benötigen, so hat dies eine Auswirkung auf alle Prozesse, deren Priorität zwischen der des Servers und des Clients liegt.
Eine Lösung zu dieser Problematik bietet die Fähigkeit von QNX, die Priorität des empfangenden Prozesses durch die Nachricht anzupassen. Wenn der Serverprozeß eine Nachricht empfängt, wird seine eigene Priorität mit der des Clients identisch. Beachten Sie bitte, daß nur die Priorität, verändert wird, nicht jedoch seine Schedulingmethode. Erreicht den Server eine weitere Nachricht, während er noch eine Anfrage bearbeitet, wird seine augenblickliche Priorität auf die der neuen Nachricht angehoben, vorausgesetzt, die Priorität der neuen Nachricht ist höher als die des Serverprozesses. Der sich ergebende Effekt ist ein Beschleunigen des augenblicklichen Bearbeitungsstandes des Servers, so daß er seine Tätigkeit mit erhöhter Priorität fertigstellen kann, um die neue Nachricht entgegenzunehmen. Gäbe es diesen Mechanismus nicht, so würde der hochpriorisierte Client blockieren und auf den Serverprozeß mit niedriger Priorität warten.
Wenn Sie sich entscheiden, clientgetriebene Prioritäten für Ihren Serverprozeß zu verwenden, sollten Sie ebenfalls dafür Sorge tragen, daß die Nachrichten in Prioritätenreihenfolge an den Serverprozeß übergeben werden (im Gegensatz zur zeitlichen Reihenfolge).
Um clientgetriebene Prioritäten zu verwenden, benutzen Sie die Funktion qnx_pflags() wie folgt:
qnx_pflags(~0, _PPF_PRIORITY_FLOAT
| _PPF_PRIORITY_REC, 0, 0);
Ein Wort zu Echtzeitperformance
Auch wenn wir es uns manchmal wünschen, sind Computer doch nicht unendlich schnell. In einer Echtzeitumgbung ist es wichtig, unnötige Maschinenzyklen zu vermeiden. Mindestens ebenso wichtig ist es, auf Ereignisse schnell zu reagieren. Gemeint ist hier die Zeit, die ein Programm vom Eintreffen des Ereignisses benötigt, um eine Codesequenz auszuführen, damit es auf das Ereignis reagieren kann. Die Zeit vom Eintreffen des Ereignisses bis zur Reaktion hierauf wird als Latenzzeit bezeichnet.
Unter QNX gibt es verschiedene Formen von Latenzzeiten.
Interrupt-Latenzzeit
Die Interrupt-Latenzzeit wird als die Zeitdifferenz zwischen dem Eintreffen (und Akzeptieren) eines Hardwareinterruptes und dem Ausführen der ersten Instruktion eines Software-Interrupthandlers definiert. QNX beläßt alle Interrupts aktiviert, so daß die Interruptlatenzzeit keine signifikante zeitliche Auswirkung hat. Es gibt jedoch manchmal die Forderung, daß Codeabschnitte gegen das Eintreffen von weiteren Interrupts geschützt werden müssen. Hierfür wird kurzzeitig ein Interrupt gesperrt, um die kritische Codesequenz auszuführen. Diese Sperrzeit definiert den schlechtesten Fall einer Interrupt-Latenzzeit - in QNX ist diese sehr klein.
Das folgende Diagramm zeigt eine Situation, bei der ein Hardwareinterrupt von einem Softwareinterrupthandler bearbeitet wird. Der Softwareinterrupthandler seinerseits führt keinen Code aus und gibt eventuell eine Proxy zurück, welche getriggert wird.
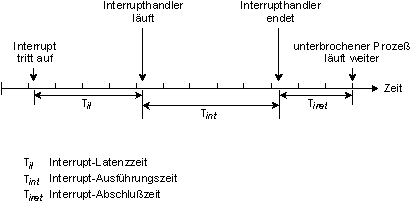
Der Interrupthandler beendet ohne Codeausführung.
Die Interrupt-Latenzzeit (Til) in obigem Diagramm zeigt die minimale Latenzzeit - für den Fall, daß alle Interrupts freigegeben sind und dann ein Interrupt eintritt. Die schlechteste Interrupt-Latenzzeit ist die oben aufgeführte plus der längsten Zeit, für die QNX oder ein QNX-Prozeß Interrupts abschaltet.
Til für verschiedene CPUs
Die folgende Tabelle zeigt typische Interrupt-Latenzzeiten (Til) für einige Prozessoren:
| Interrupt-Latenzzeit (Til): | Prozessor: |
|---|---|
| 3.3 microsec | 166 MHz Pentium |
| 4.4 microsec | 100 MHz Pentium |
| 5.6 microsec | 100 MHz 486DX4 |
| 22.5 microsec | 33 MHz 386EX |
Scheduling-Latenzzeit
In manchen Fällen ist es erforderlich, daß ein Interrupthandler einen regulären Prozeß benachrichtigen, bzw. anwerfen muß. Dies geschieht, indem der Interrupthandler eine Proxy zurückgibt, welche getriggert und an den wartenden Prozeß ausgeliefert wird. Dies führt zu einer weiteren Verzögerung - Scheduling-Latenzzeit - welcher man entsprechende Aufmerksamkeit widmen muß.
Die Scheduling-Latenzzeit ist die Zeit zwischen der Beendigung eines Interrupthandlers und der Ausführung des ersten Befehls eines Treiberprozesses. Diese Zeitdifferenz entsteht, da der Prozeßkontext des augenblicklich laufenden Prozesses gesichert und der neue Kontext für den zu startenden Prozeß wiederhergestellt werden muß. Obwohl dieser Zeitabschnitt größer ist als die Interruptlatenzzeit, ist er in QNX extrem klein.
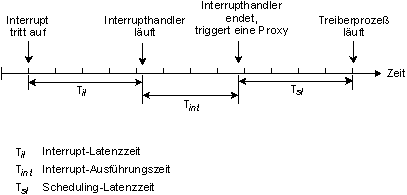
Interrupthandler gibt eine Proxy zurück, wenn er terminiert.
Es ist wichtig an dieser Stelle zu bemerken, daß die meisten Interruptroutinen keine Proxies zurückgeben müssen, da sie die vollständige Kontrolle über die Hardware haben. Das Abfeuern einer Proxy, um einen Treiberprozeß anzuwerfen, ist nur bei signifikanten Ereignissen nötig. So reagiert zum Beispiel der Interrupthandler einer seriellen Schnittstelle nur auf den Sende-Interrupt des Bausteins, bis der Ausgabepuffer vollständig entleert ist. Nur das Ereignis Ausgabepuffer leer wird durch eine Proxy an den verwaltenden Prozeß (Dev) gemeldet.
Tsl für verschiedene CPUs
Diese Tabelle zeigt eine typische Scheduling-Latenzzeit (Tsl) für einige Prozessoren:
| Scheduling-Latenzzeit (Tsl): | Prozessor: |
|---|---|
| 4.7 microsec | 166 MHz Pentium |
| 6.7 microsec | 100 MHz Pentium |
| 11.1 microsec | 100 MHz 486DX4 |
| 74.2 microsec | 33 MHz 386EX |
Gestapelte Interrupts
Da Mikrocomputerarchitekturen es zulassen, für Hardwareinterrupts Prioritäten zu vergeben, können hochpriorisierte Interrupts niedriger priorisierte verdrängen.
Dieser Mechanismus wird von QNX vollständig unterstützt. Das vorhergehende Szenario beschreibt den einfachsten - und gebräuchlisten - Fall, bei dem zu einem Zeitpunkt nur ein Interrupt auftritt. Dieses zeitliche Verhalten gilt ebenfalls für den Interrupt mit der höchsten Priorität im System, da dieser nicht verdrängt werden kann. Für Interrupts mit niedriger Priorität gelten andere Gesetze, weil sie von höherpriorisierten verdrängt werden können.
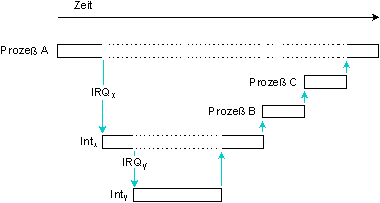
Prozeß A läuft. Interrupt IRQx bewirkt, daß Interrupthandler Intx gestartet wird. Dieser wird von IRQy und seinem Handler Inty verdrängt. Inty triggert eine Proxy, um Prozeß B anzuwerfen; Intx triggert eine Proxy, um Prozeß C zu starten.