
 Deutsch
Deutsch  English
English Kapitel 3 - Der Prozeß-Manager
Der Prozeß-Manager
Dieses Kapitel beinhaltet die folgenden Themen:
- Einführung
- Der Lebenszyklus eines Prozesses
- Prozeßzustände
- Symbolische Prozeßnamen
- Timer
- Interrupthandler
Einführung
Aufgaben des Prozeß-Managers
Der Prozeß-Manager arbeitet eng mit dem Mikrokernel zusammen, um wesentliche Dienste des Betriebssystems bereitzustellen. Obwohl er den gleichen Adressraum nutzt wie der Mirokernel (und damit auch der einzige ist), läuft der Prozeß-Manager als ein echter Prozeß. Als solcher wird er vom Mikrokernel wie alle anderen Prozesse eingeplant und er benutzt die Grundlagen des Message-Passing des Mikrokernels, um mit anderen Prozessen im System zu kommunizieren.
Der Prozeß-Manager ist verantwortlich für die Erzeugung neuer Prozesse im System und er verwaltet außerdem die meisten fundamentalen Ressourcen, welche zu einem Prozeß gehören. Diese Dienste werden alle über Nachrichten angeboten. Will zum Beispiel ein laufender Prozeß einen neuen Prozeß erzeugen, macht er dies, indem er eine Nachricht verschickt, welche die Details des neu zu erzeugenden Prozesses beinhaltet. Da Nachrichten netzwerkweit funktionieren, kann eine Nachricht zum Erzeugen eines neuen Prozesses einfach an den Prozeß-Manager des entfernten Knoten versendet werden.
Funktionen für die Prozeßerzeugung
QNX unterstützt drei Funktionen für die Prozeßerzeugung:
- fork()
- exec()
- spawn()
Sowohl fork() als auch exec() sind in POSIX definiert, während die Implementation von spawn() einzigartig für QNX ist.
fork()
Die fork() Funktion erzeugt einen neuen Prozeß, welcher ein exaktes Image des rufenden Prozesses ist. Der neue Prozeß teilt den gleichen Code wie der rufende Prozeß und vererbt eine Kopie aller Prozeßdaten des rufenden Prozesses.
exec()
Die exec() Funktion ersetzt das Image des rufenden Prozesses durch ein neues Image. Aus einer erfolgreichen exec() gibt es keine Rückkehr, da das neue Prozeßimage das Image des rufenden Prozesses im Speicher ersetzt. Es gilt als allgemeine Praxis in POSIX-Systemen einen neuen Prozeß zu kreieren, indem der aufrufende Prozeß sich selbst durch fork() dupliziert und der Sohnprozeß dann seinerseits exec() aufruft, um sich selbst durch einen neuen Prozeß zu ersetzen.
spawn()
Die spawn() Funktion erzeugt einen neuen Prozeß als Sohnprozeß des aufrufenden Prozesses. Es kann die Notwendigkeit von fork() und exec() ersetzen, was bedeutet, daß die Erzeugung neuer Prozesse schneller und effizienter durchgeführt werden kann. Im Gegensatz zu fork() und exec(), welche durch ihre Natur auf dem gleichen Knoten wie der aufrufende Prozeß operieren, kann die spawn() Funktion Prozesse auf jedem Knoten im Netzwerk kreieren.
Prozeßvererbung
Wenn ein Prozeß durch eine der gerade beschriebenen Funktionen erzeugt wird, erbt er vieles seiner Umgebung von seinem Vaterprozeß. In der folgenden Tabelle ist dieses zusammengefasst:
| Vererbtes Objekt | fork() | exec() | spawn() |
|---|---|---|---|
| Prozeß ID | nein | ja | nein |
| geöffnete Dateien | ja | optional* | optional |
| Verriegelungen (file locks) | nein | ja | nein |
| Anstehende Signale | nein | ja | nein |
| Signal-Masken | ja | optional | optional |
| Ignorierte Signale | ja | optional | optional |
| Signalhandler | ja | nein | nein |
| Umgebungsvariablen | ja | optional | optional |
| Session ID | ja | ja | optional |
| Prozeßgruppe | ja | ja | optional |
| echte UID, GID | ja | ja | ja |
| effektive UID, GID | ja | optional | optional |
| gegenwärtiges Arbeitsverzeichnis | ja | optional | optional |
| Dateierzeugungsmaske | ja | ja | ja |
| Priorität | ja | optional | optional |
| Schedulermethode (scheduler policy) | ja | optional | optional |
| virtuelle Verbindung | nein | nein | nein |
| Symbolische Namen | nein | nein | nein |
| Echtzeit-Timer | nein | nein | nein |
*optional: der Aufrufende kann je nach Bedarf auswählen.
Der Lebenszyklus eines Prozesses
Ein Prozeß durchläuft vier Phasen:
- Erzeugen
- Laden
- Ausführen
- Beenden
Erzeugen
Eine Prozeßerzeugung besteht aus der Zuteilung einer Prozeß ID für den neuen Prozeß und dem Bereitstellen der Informationen, welche die Umgebung des neuen Prozesses definieren. Die meisten dieser Informationen werden von dem Vaterprozeß an den neuen Prozeß vererbt. (Sehen Sie den vorhergehenden Abschnitt bei ``Prozeßvererbung'').
Laden
Das Laden eines Prozesses wird durch einen Loader Thread erledigt. Der Code zum Laden eines Prozesses liegt im Prozeß-Manager, er läuft jedoch als ein eigener Programmfaden (Thread) unter der Prozeß ID des neuen Prozesses. Das ermöglicht dem Prozeß-Manager weitere Anfragen zu verarbeiten, während andere Programme geladen werden.
Ausführen
Sobald der Programmcode geladen ist, ist der Prozeß bereit zur Ausführung; er beginnt, sich mit anderen Prozessen um CPU-Ressourcen zu bewerben. Beachten Sie, daß alle Prozesse mit Ihren Vaterprozessen konkurrieren. Außerdem bedeutet das Ende eines Vaterprozesses nicht automatisch das Ende seines Sohnprozesses.
Beenden
Ein Prozeß wird in einer von zwei Arten beendet:
- es wird ein Signal an den Prozeß ausgeliefert, mit der definierten Aktion den Prozeß zu beenden
- der Prozeß ruft exit() auf, entweder explizit oder als Standardaktion, wenn er von main() zurückkehrt
Die Prozeßbeendung durchläuft zwei Stadien:
- Ein Beendungs-Threadläuft im Prozeß-Manager. Dieser Code liegt im Prozeß-Manager, aber er läuft als Programmfaden (Thread) mit der Prozeß ID des zu beendenden Prozesses. Dieser Thread schließt alle geöffneten Dateiedeskriptoren und gibt die folgenden Ressourcen frei:
- alle virtuellen Verbindungen des Prozesses
- dem Prozeß zugeordneter Speicher
- alle symbolischen Namen
- alle Hauptgerätenummern (nur I/O-Manager)
- alle Interrupthandler
- alle Proxies
- alle Timer
- Nach der Beendung dieses Thread wird der Vaterprozeß darüber informiert, daß der Sohnprozeß beendet wurde (diese Phase läuft im Prozeß-Manager ab).
Wenn der Vaterprozeß keinen wait() oder waitpid() Aufruf abgesetzt hat, wird der Sohnprozeß zu einem ``Zombie''-Prozeß und solange nicht beendet, bis der Vaterprozeß ein wait() absetzt oder endet. (Wenn Sie nicht wollen, daß ein Prozeß auf die Beendung eines Sohnprozesses wartet (wait), sollten Sie ebenfalls das _SPAWN_NOZOMBIE Flag mit qnx_spawn() nutzen oder die Aktion für SIGCHLD auf SIG_IGN über signal() setzen. Auf diesem Weg werden Sohnprozesse nicht zu Zombies wenn sie enden.)
Ein Vaterprozeß kann auf das Ende eines Sohnes, ausgeführt auf einem entfernten Knoten, warten (wait()). Sobald der Vater eines Zombies endet, wird der Zombie ebenfalls gelöscht.
Wird ein Prozeß durch die Auslieferung eines Beendungssignals beendet und das dumper Utility läuft, wird ein Speicher- Image-Dump generiert. Sie können diesen Dump mit dem symbolischen Debugger prüfen.
Prozeßzustände
Ein Prozeß befindet sich immer in einem der folgenden Zustände:
- READY - der Prozeß könnte die CPU nutzen (z. B. wartet er nicht auf das Eintreten eines Ereignisses).
- BLOCKED - der Prozeß befindet sich in einem der folgenden blockierenden Zustände:
- SEND-blockiert
- RECEIVE-blockiert
- REPLY-blockiert
- SIGNAL-blockiert
- SEMAPHORE-blockiert
- HELD - der Prozeß hat ein SIGSTOP Signal erhalten. Solange sich ein Prozeß im Zustand HELD befindet, wird ihm die Benutzung der CPU verweigert; die einzige Möglichkeit seinen HELD-Status zu ändern ist, entweder ein SIGCONT-Signal an ihn auszuliefern oder den Prozeß über ein Signal zu beenden.
- WAIT - Der Prozeß hat einen wait() oder waitpid() Aufruf abgeschickt, um auf Statusinformationen von einem oder mehreren seiner Sohnprozesse zu warten.
- DEAD - der Prozeß hat sich beendet, ist aber nicht in der Lage seinen Zustand an seinen Vaterprozeß zu senden, weil dieser kein wait() oder waitpid() abgesetzt hat. Ein Prozeß mit Zustand DEAD existiert zwar noch, aber der Speicherbereich, den er einmal eingenommen hat, ist bereits freigegeben. Ein Prozeß mit Zustand DEAD ist auch bekannt als ein Zombie-Prozeß.
| Für mehr Informationen über Prozeßzustände, lesen Sie Kapitel 2, Der Mikrokernel. |
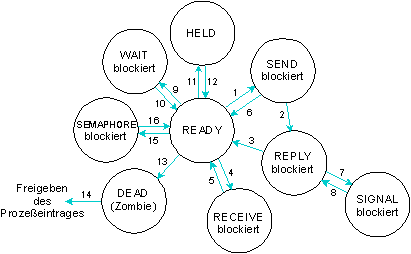
Mögliche Prozeßzustände in einem QNX System.
Die im vorhergehenden Diagramm dargestellten Transaktionen:
- Prozeß sendet Nachricht.
- Zielprozeß erhält die Nachricht.
- Zielprozeß antwortet.
- Prozeß wartet auf die Nachricht.
- Prozeß erhält Nachricht.
- Signal hebt die Blockierung des Prozesses auf.
- Signal versucht die Blockierung des Prozesses aufzuheben; Empfänger hat einen Signalhandler installiert
- Zielprozeß erhält die Signalnachricht
- Prozeß wartet auf das Ende eines Sohnprozesses.
- Sohnprozeß endet oder ein Signal hebt die Blockierung des Prozesses auf.
- Prozeß empfängt SIGSTOP-Signal.
- Prozeß empfängt SIGCONT-Signal.
- Prozeß endet.
- Vaterprozeß wartet auf Beendung, beendet sich selber oder ist bereits beendet.
- Prozeß ruft semwait() auf einer nicht-positiven Semaphore auf.
- Ein anderer Prozeß ruft sempost() auf oder ein unmaskiertes Signal wird ausgeliefert.
Erfragen von Prozeßzuständen
Um den Zustand eines individuellen Prozesses aus der Shell heraus zu bestimmen, benutzen Sie die ps und sin Werkzeuge (aus Anwendungen heraus benutzen Sie die qnx_psinfo() Funktion).
Um den Zustand des Betriebssystems im Ganzen aus der Shell heraus zu bestimmen, benutzen Sie das sin Kommando (aus Anwendungen heraus nutzen Sie die qnx_osinfo() Funktion).
Das ps Kommando wird durch POSIX definiert; die Benutzung dieses Kommandos ist eventuell portierbar. Auf der anderen Seite ist das sin-Kommando einzigartig für QNX; es gibt Ihnen hilfreiche QNX-spezifische Informationen, welche Sie von dem ps Kommando nicht erhalten.
Symbolische Prozeßnamen
QNX unterstützt die Entwicklung von Applikationen, welche in kooperierende Prozesse aufgeteilt sind. Eine Applikation, welche aus mehreren kooperierenden Prozessen besteht, besitzt eine höhere Effizienz und kann im Netzwerk verteilt werden, um größere Performance zu erlangen.
Wie auch immer, die Aufteilung von Applikationen in kooperierende Prozesse erfordert besondere Überlegungen. Wenn kooperierende Prozesse zuverlässig miteinander kommunizieren sollen, müssen sie fähig sein, die jeweilige Prozeß ID untereinander zu bestimmen. Nehmen wir beispielsweise an, Sie haben einen Datenbank-Server-Prozeß, welcher Dienste für eine beliebige Anzahl Clients bereitstellt. Die Clients laufen zu unterschiedlichen Zeitpunkten, aber der Server bleibt immer verfügbar. Wie können Clientprozesse die Prozeß ID des Datenbank-Servers herausfinden, um ihm Nachrichten zu senden?
In QNX geben sich die Prozesse selber symbolische Namen. Im Kontext eines einzelnen Knotens können Prozesse diesen Namen mit dem Prozeß-Manager auf dem Knoten, wo sie laufen, registrieren. Andere Prozesse können dann den Prozeß-Manger nach der mit dem Namen assoziierten Prozeß ID befragen.
In einer Netzwerkumgebung, wo ein Server möglicherweise Clients von verschiedenen Knoten über das Netzwerk versorgen muß, wird die Situation um einiges komplexer. Deshalb unterstützt QNX die Möglichkeit, sowohl globale als auch lokale Namen zu unterstützen. Globale Namen sind über das Netzwerk bekannt, wohingegen lokale Namen nur auf dem Knoten, auf dem sie registriert sind, existieren. Globale Namen beginnen mit einem Slash (/). Zum Beispiel:
| qnx/fsys | lokaler Name |
| Firma/xyz | lokaler Name |
| /Firma/xyz | globaler Name |
| Wir empfehlen, daß Sie alle Ihre Namen mit Ihrem Firmennamen einleiten, um Namenskonflikte zwischen Herstellern zu vermeiden. |
Um globale Namen benutzen zu können, muß ein Prozeß, bekannt als ein Prozeß-Name-Locator (z. B. das nameloc Werkzeug) auf zumindest einem Knoten in einem Netzwerk laufen. Dieser Prozeß pflegt alle registrierten globalen Namen.
Bis zu zehn Prozeß Name Locator können gleichzeitig in einem Netzwerk aktiv sein. Jeder pflegt eine identische Kopie aller aktiven globalen Namen. Diese Redundanz stellt sicher, daß ein Netzwerk weiterhin funktioniert, selbst wenn ein oder mehrere Knoten, welche Prozeß Name Locator betreiben, gleichzeitig ihren Dienst verweigern.
Um einen Namen abzulegen, benutzt ein Server-Prozeß die qnx_name_attach() Funktion. Um einen Prozeß mit seinem Namen zu lokalisieren, benutzt ein Client-Prozeß die Funktion qnx_name_locate().
Timer
Zeitverwaltung
In QNX basiert die Zeitverwaltung auf einem Systemzeitgeber, verwaltet vom Betriebssystem. Dieser Zeitgeber, im folgenden Timer genannt, beinhaltet die Coordinated Universal Time (UTC), relativ zu 0 Stunden, 0 Minuten, 0 Sekunden, 1. Januar 1970. Um die lokale Zeit zu bestimmen, benutzen die Zeitverwaltungsfunktionen die TZ Umgebungsvariable (welche im Handbuch Installation & Konfiguration beschrieben wird).
Einfache Zeitfunktionen
Shell-Skripte und Prozesse können für eine bestimmte Anzahl an Sekunden pausieren, indem sie eine einfache Zeitfunktion benutzen. Für Shell-Skripte wird diese Möglichkeit durch das sleep Kommando unterstützt; für Prozesse durch die sleep() Funktion. Sie können auch die delay() Funktion benutzen, um ein Zeitintervall in Millisekunden zu benutzen.
Leistungsfähige Zeitfunktionen
Ein Prozeß kann Zeitgeber kreieren, sie mit einem Zeitintervall ausstatten und diese wieder entfernen. Diese komfortable Zeitverwaltung basiert auf der Spezifikation von POSIX 1003.1b.
Zeitgeber (Timer) erzeugen
Ein Prozeß kann einen oder mehrere Zeitgeber erzeugen. Diese Zeitgeber können eine Mischung aus jeglichen unterstützten Timertypen sein, abhängig von einem konfigurierbaren Limit der maximalen Anzahl von Zeitgebern die vom Betriebssystem unterstützt werden (siehe Proc in der Utilities Reference). Um Zeitgeber zu erzeugen, benutzen Sie die Funktion timer_create().
Zeitgeber (Timer) konfigurieren
Sie können Zeitgeber mit den folgenden Zeitintervallen konfigurieren:
- absolut - die Zeit, relativ zu 0 Stunden, 0 Minuten, 0 Sekunden, 1. Januar 1970.
- relativ - die Zeit, relativ zur momentanen Uhrzeit.
Sie haben außerdem Timer zur Verfügung, welche zyklisch und absolut eingeplant werden können, also Start des Timers zu einem absoluten Zeitpunkt und danach zyklisch mit der voreingestellten Intervallrate. Nehmen wir zum Beispiel an, sie haben einen Timer so eingerichtet, daß er morgen Früh um 9 Uhr startet. Sie können angeben, daß er danach alle 5 Minuten erneut startet.
Sie können auch ein neues Zeitintervall für einen existierenden Timer setzen. Die Auswirkung des neuen Zeitintervalls hängt von dem Intervalltyp ab:
- für einen absoluten Timer ersetzt das neue Intervall das vorherige
- für einen relativen Timer wird das neue Intervall zu jedwedem verbleibendem Zeitintervall hinzugefügt
| Um einen Timer zu konfigurieren: | Benutzen Sie die Funktion: |
|---|---|
| für ein absolutes oder relatives Zeitintervall | timer_settime() |
Zeitgeber (Timer) entfernen
Um Timer zu entfernen, benutzen Sie die Funktion timer_delete().
Setzen der Timerauflösung
Sie können die Auflösung des Timers setzen, indem Sie das ticksize Kommando oder die qnx_ticksize() Funktion nutzen. Die Auflösung läßt sich auf einen Bereich zwischen 500 Mikrosekunden und 50 Millisekunden einstellen.
Zeitgeber (Timer) lesen
Um den Restwert eines Intervalltimers auszulesen oder um zu überprüfen, ob der Timer entfernt wurde, benutzen Sie die timer_gettime() Funktion.
Interrupthandler
Interrupthandler bedienen das Hardwaresystem des Computers - sie reagieren auf Hardwareinterrupts und verwalten den Transfer von Daten auf unterster Stufe zwischen dem Computer und externen Geräten.
Interrupthandler sind physikalisch in den Code eines Standard-QNX-Prozesses eingebettet (z. B. ein Treiber), aber Sie laufen immer asynchron zu dem ihnen zugeordneten Prozeß.
Ein Interrupthandler:
- wird mit einem ``far''-Aufruf angesprochen, jedoch nicht direkt vom Interrupt selbst (deshalb kann er in C geschrieben werden, besser als in Assembler)
- läuft in dem Kontext des Prozesses, in dem er eingebettet ist. So hat er Zugriff auf alle globalen Variablen des Prozesses.
- läuft mit freigegebenen (eingeschalteten) Interrupts, wird aber nur verdrängt, wenn ein Interrupt mit höherer Priorität auftritt.
- sollte den 8259 Interruptbaustein nicht direkt ansprechen (das Betriebssystem verwaltet ihn selbst)
- sollte so kurz wie möglich sein.
Viele Prozesse können auf den gleichen Interrupt zugreifen (wenn die Hardware dies unterstützt). Wenn ein physikalischer Interrupt auftritt, wird nacheinander jedem Interrupthandler die Kontrolle übergeben. Es sollte keine Vermutung darüber gemacht werden, in welcher Reihenfolge ein Interrupthandler, welcher sich einen Hardwareinterrupt teilt, aufgerufen wird.
| Wollen Sie: | Benutzen Sie die Funktion: |
|---|---|
| einen Hardwareinterrupt installieren | qnx_hint_attach() |
| einen Hardwareinterrupt entfernen | qnx_hint_detach() |
Interrupthandler für Timer
Sie können einen Interrupthandler direkt für den Systemzeitgeber registrieren, so daß der Handler bei jedem Timerinterrupt aufgerufen wird. Um die Periode zu setzen, benutzen Sie das Werkzeug ticksize.
Sie können auch auf einen skalierten Timerinterrupt zugreifen, der alle 50 Millisekunden aktiviert wird, unabhängig von dem ticksize. Diese Zeitgeber bieten eine einfache Alternative zu den POSIX 1003.4 Timern.